Theorie (Mathematik) hinter Generativer KI¶
Wahrscheinlichkeitsmodelle: Grundlagen der statistischen Modellierung.
Transformer-Architektur: Encoder-Decoder-Strukturen, Attention-Mechanismen und Selbstaufmerksamkeit.
Optimierungsalgorithmen: Überblick über gängige Verfahren wie Adam und ihre mathematischen Grundlagen.
Wahrscheinlichkeitsmodelle - die Grundlage Generativer KI¶
Statistische Modellierung bildet die mathematische Grundlage hinter der Generativen KI. Generative KI-Modelle basieren auf dem Prinzip, die zugrunde liegende Wahrscheinlichkeitsverteilung der Trainingsdaten zu erlernen. Dabei wird angenommen, dass die beobachteten Daten aus einer bestimmten, aber oft unbekannten Verteilung stammen. Durch die Anwendung von Konzepten wie der Maximum-Likelihood-Schätzung und der Minimierung der Kreuzentropie wird versucht, diese Verteilung zu approximieren. Dies bildet die Grundlage dafür, dass das Modell anschließend in der Lage ist, neue, statistisch konsistente Datenpunkte zu generieren, die den Mustern und Strukturen der Trainingsdaten entsprechen.
1.1 Bedingte Wahrscheinlichkeiten¶
LLMs berechnen die Wahrscheinlichkeit eines Tokens basierend auf dem bisherigen Kontext:
Das bedeutet: Die Wahrscheinlichkeit für ein ganzes Textstück ergibt sich durch das Produkt der Wahrscheinlichkeiten für jedes Token, gegeben alle vorhergehenden.
Generative Modelle basieren darauf, die zugrunde liegende Wahrscheinlichkeitsverteilung der Daten zu approximieren. Dabei geht man davon aus, dass jedes Datenbeispiel (x) mit einer Wahrscheinlichkeit (P(x)) aus einer (meist unbekannten) Verteilung stammt. Das Ziel ist es, ein Modell mit Parametern (theta) so anzupassen, dass es diese Verteilung möglichst gut erfasst.
Ein gängiger Ansatz hierfür ist die Maximum-Likelihood-Schätzung (MLE). Die Likelihood-Funktion für (N) unabhängige Datenbeispiele lautet:
Statt direkt diese Funktion zu maximieren, wird oft der negative Log-Likelihood minimiert:
1.2 Sprachmodellierung als Prädiktion¶
Die Aufgabe eines Sprachmodells ist es, das nächste Token vorherzusagen – also den Output mit der höchsten Wahrscheinlichkeit auszugeben. Dies ist ein typisches Beispiel für ein bedingtes Wahrscheinlichkeitsmodell.
1.3 Entropie & Log-Loss¶
Die Modelloptimierung erfolgt durch Minimierung des Cross-Entropy Loss, der misst, wie gut die Verteilung des Modells mit der echten Verteilung der Trainingsdaten übereinstimmt.
In der Praxis wird häufig die Kreuzentropie (Cross-Entropy; siehe Kreuzentropie (Wikipedia)) als Verlustfunktion verwendet, um den Unterschied zwischen der wahren Datenverteilung und der vom Modell geschätzten Verteilung zu quantifizieren.
Generative KI basiert im Kern auf Wahrscheinlichkeitsmodellen, die darauf abzielen, die Wahrscheinlichkeitsverteilung von Sequenzen zu modellieren.
Transformer-Architektur¶
Die Transformer-Architektur bildet das Rückgrat moderner generativer Modelle und hat die Art und Weise revolutioniert, wie Sequenzdaten verarbeitet werden – insbesondere in der Generierung von Texten. Sie verzichtet auf rekurrente Strukturen und setzt stattdessen vollständig auf Attention-Mechanismen.
Die wichtigsten Bestandteile dieser Architektur sind:
Self-Attention, Multi-Head-Attention und Feed-Forward-Netzwerke.
Self-Attention:
Im Zentrum steht das Konzept der Selbstaufmerksamkeit (Self-Attention), das dem Modell ermöglicht, Beziehungen zwischen allen Elementen einer Eingabesequenz simultan zu berücksichtigen.
Jeder Eingabesequenz werden drei unterschiedliche Vektorrepräsentationen zugeordnet:
Query (Q)
Key (K)
Value (V)
Die Self-Attention berechnet, wie stark jedes Element einer Sequenz mit allen anderen in Beziehung steht. Dies erfolgt über die folgende Berechnung:
Hierbei ist (d_k) die Dimension der Key-Vektoren. Die Division durch (sqrt{d_k}) verhindert, dass die resultierenden Werte zu groß werden und die Softmax-Funktion verzerrt.
Multi-Head-Attention:
Die Multi-Head-Attention erlaubt es dem Modell, verschiedene Aspekte der Beziehungen in parallelen „Aufmerksamkeits-Köpfen“ zu betrachten.
Anstatt nur eine einzige Attention-Berechnung durchzuführen, wird der Mechanismus in mehrere parallele „Köpfe“ (Heads) aufgeteilt. Jeder Kopf führt eine eigene Attention-Berechnung durch und fokussiert dabei auf unterschiedliche Aspekte der Eingabesequenz. Die Resultate der einzelnen Köpfe werden anschließend zusammengeführt, um eine reichhaltige, kontextabhängige Darstellung zu erhalten.
Feed-Forward-Netzwerke:
Nach der Attention folgt ein vollständig verbundenes Feed-Forward-Netzwerk, das positionweise auf jede Eingaberepräsentation angewandt wird. Typischerweise besteht dieses Netzwerk aus zwei linearen Transformationen mit einer nichtlinearen Aktivierungsfunktion (z. B. ReLU) dazwischen, die für die Modellierung komplexer Zusammenhänge notwendig sind:
Diese Schicht hilft dabei, die aus der Attention extrahierten Merkmale weiter zu verarbeiten und komplexe nichtlineare Zusammenhänge zu modellieren.
Somit ermöglichen diese Mechanismen es, längere Abhängigkeiten und feinkörnige Details in Sequenzdaten zu erfassen, was wesentlich zur Qualität der generierten Inhalte beiträgt.
Zusätzliche Elemente:
Residual-Verbindungen: Diese addieren den Eingang einer Schicht zu ihrem Ausgang, um den Informationsfluss zu verbessern und das Verschwinden von Gradienten zu verhindern.
Layer-Normalization: Eine Normierungstechnik, die dazu beiträgt, die Stabilität und Effizienz des Trainings zu erhöhen.
Ein typischer Transformer-Block besteht somit aus:
Multi-Head-Self-Attention
Add & Norm (Residual-Verbindung plus Layer-Normalization)
Feed-Forward-Netzwerk
Add & Norm (erneut Residual-Verbindung plus Layer-Normalization)
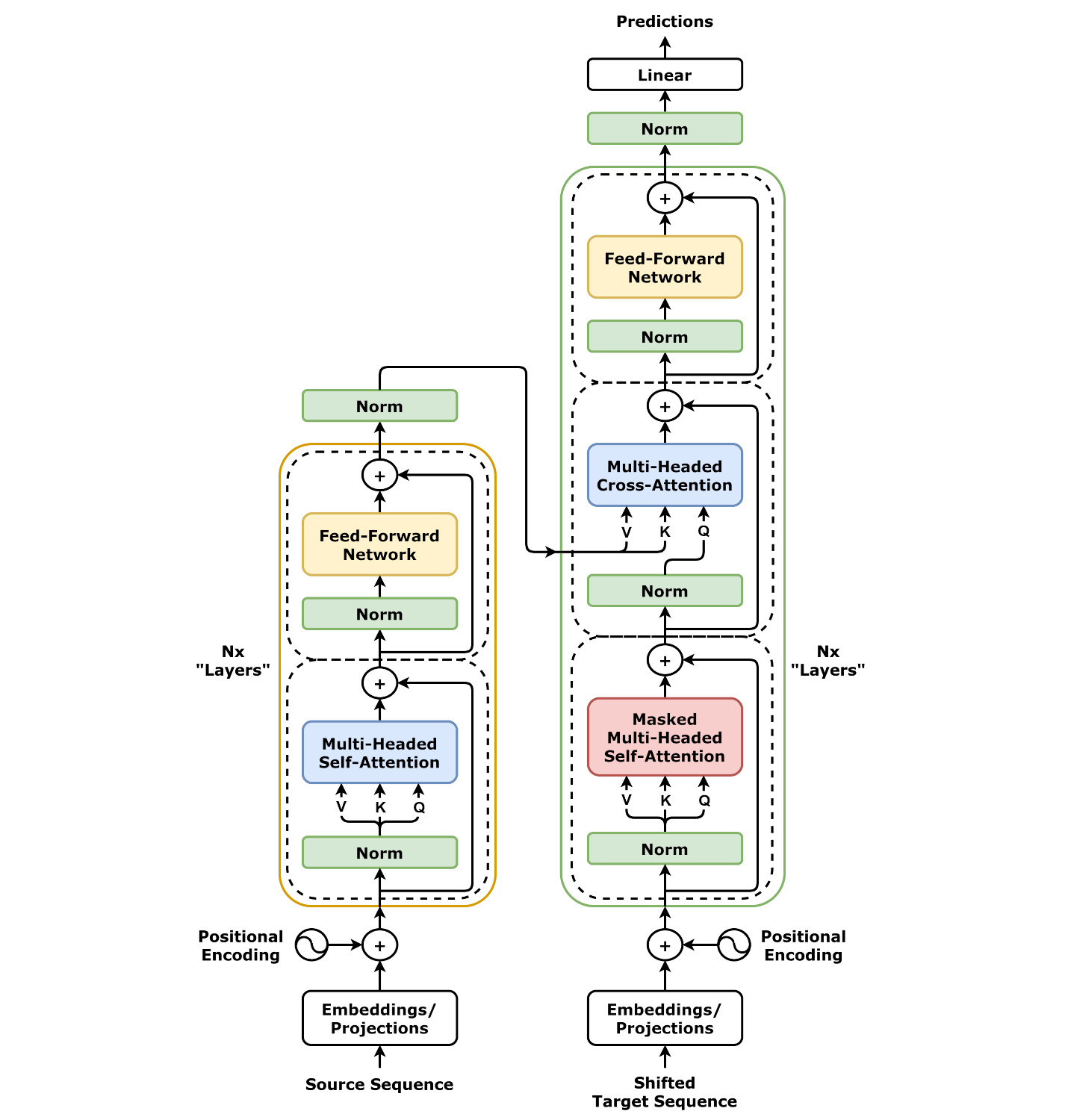
Abbildung 1: Transformer-Modellarchitektur mit originaler Position der Layer-Normalisierung. [1] [2]¶
Optimierungsalgorithmen¶
Der Trainingsprozess generativer Modelle (so wie bei generell allen Deep-Learning-Modellen) basiert auf iterativen Optimierungsmethoden, bei denen die Modellparameter so angepasst werden, dass der Fehler (Verlustfunktion) zwischen den generierten und den echten Daten minimiert wird. Zentral hierbei ist der Einsatz von Gradientenabstiegsverfahren. Neben dem klassischen Gradientenabstieg existieren verschiedene weiterentwickelte Algorithmen, die adaptive Lernraten und Momentum nutzen.
Grundlegender Gradientenabstieg:
Beim grundlegenden Gradientenabstieg wird bei jedem Schritt die Parameteraktualisierung wie folgt durchgeführt:
wobei (eta) die Lernrate ist und (nabla L(theta_t)) den Gradienten der Verlustfunktion bezüglich der Parameter (theta_t) darstellt.
AdaGrad:
AdaGrad passt die Lernrate für jeden Parameter individuell an, indem es die Summe der Quadrate der bisherigen Gradienten berücksichtigt. Dabei bezeichnet (g_t = nabla L(theta_t)) den Gradienten der Verlustfunktion. Für den Parameter (theta_i) erfolgt die Aktualisierung:
Dabei akkumuliert (G_{t,ii}) die Summe der Quadrate der Gradienten für (theta_i) bis zum Zeitpunkt (t) und (epsilon) ist eine kleine Konstante zur Vermeidung einer Division durch Null. AdaGrad ist besonders nützlich bei spärlichen Daten, führt aber manchmal zu einer zu schnellen Reduktion der Lernrate.
RMSProp:
RMSProp modifiziert AdaGrad, indem es statt der kumulierten Summe einen exponentiell gewichteten gleitenden Durchschnitt der quadratischen Gradienten verwendet. Dies verhindert, dass die Lernrate zu stark abnimmt:
Hierbei ist (gamma) ein Zerfallsfaktor, der bestimmt, wie stark frühere Gradienten gewichtet werden.
Adam (Adaptive Moment Estimation):
Adam kombiniert die Ideen von RMSProp mit der Integration von Momentum. Es berechnet sowohl einen gleitenden Durchschnitt der Gradienten als auch der quadrierten Gradienten:
Da die Schätzungen in den ersten Schritten verzerrt sein können, werden sie wie folgt korrigiert:
Die Parameter werden dann aktualisiert mittels:
Adam vereint somit die Vorteile von AdaGrad und RMSProp und ist weit verbreitet, weil es die Lernraten dynamisch anpasst und stabile Konvergenzen auch in tiefen Netzwerken ermöglicht.
Die Wahl und Konfiguration des Optimierungsalgorithmus ist entscheidend für die Trainingsdynamik und die Leistungsfähigkeit des endgültigen Modells.
Footnotes