Neuronale Netze und Deep Learning – Optimierung¶
Optimierung: Modellparameter effizient anpassen¶
Die Wahl der richtigen Optimierungsmethode ist entscheidend für die Leistung eines Modells. Optimierung bedeutet, dass wir die Modellparameter so anpassen, dass der Fehler minimiert wird und das Modell möglichst gut generalisiert. Dabei gibt es verschiedene Ansätze, die in den folgenden Unterabschnitten erklärt werden.
Grundlagen der Optimierung¶
Jedes Machine-Learning-Modell hat eine Kosten- oder Verlustfunktion (Loss Function), die misst, wie gut oder schlecht das Modell Vorhersagen trifft.
Ziel der Optimierung ist es, diese Verlustfunktion zu minimieren.
Dabei suchen wir die optimalen Modellparameter (z. B. Gewichte in neuronalen Netzen oder Koeffizienten in linearen Modellen), sodass der Fehler möglichst klein ist.
Gradient Descent – Das Fundament der Optimierung¶
Gradient Descent (Gradientenabstieg) ist eine der häufigsten Optimierungstechniken.
Dessen Ziel liegt darin, den minimalen Verlustwert (Loss) zu finden.
Dabei wird die Ableitung der Verlustfunktion verwendet, um herauszufinden, in welche Richtung sich die Parameter ändern müssen, um den Fehler zu minimieren.
w: Modellparameter (z. B. Gewichte in einem neuronalen Netz)
L: Verlustfunktion (Loss Function)
alpha: Lernrate – bestimmt, wie große Schritte das Modell bei der Optimierung macht
Varianten von Gradient Descent¶
Batch Gradient Descent:
Verwendet den gesamten Trainingsdatensatz, um den Gradienten zu berechnen.
Vorteil: Konvergiert stabil.
Nachteil: Kann sehr langsam sein, insbesondere bei großen Datensätzen.
Stochastic Gradient Descent (SGD):
wird als stochastische Approximation der Gradientenabstiegsoptimierung betrachtet:
sie ersetzt den tatsächlichen Gradient (berechnet aus dem gesamten Datensatz) durch eine Schätzung davon (berechnet aus einer zufällig selektierten Teilmenge der Daten)
Vorteil: Schneller als Batch Gradient Descent, da es nach jeder Instanz ein Update gibt.
Nachteil: Kann aufgrund der ständigen Updates stark schwanken (stochastisches Verhalten).
Mini-Batch Gradient Descent:
Ein Kompromiss zwischen Batch und SGD – nutzt kleine Gruppen (Batches) von Daten.
Vorteil: Stabiler als SGD, aber effizienter als Batch.
Nachteil: Erfordert eine optimale Wahl der Batch-Größe.
Beispiel: Auswirkungen der Lernrate auf das Training
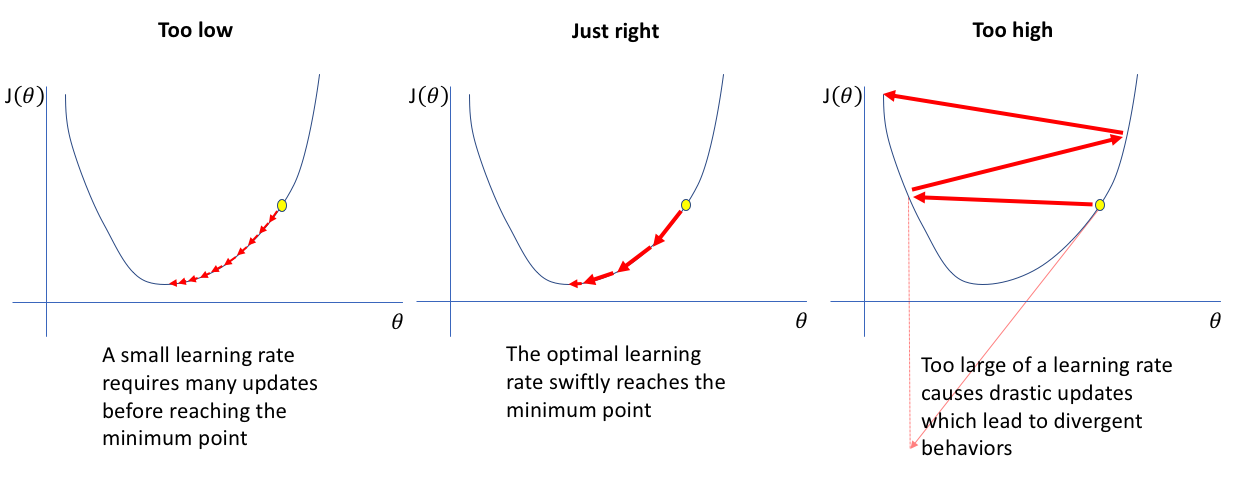
Abbildung 2: Eine zu hohe Lernrate konvergiert nicht, eine zu niedrige dauert zu lange.¶
Erweiterte Optimierungsverfahren¶
Neben Gradient Descent gibt es weiterentwickelte Algorithmen, die schneller oder stabiler konvergieren:
Momentum-based Methoden¶
Momentum Optimizer:
Verwendet einen Impulswert, um den Lernprozess zu beschleunigen und Schwankungen zu verringern.
Formell wird ein „Momentumeffekt“ hinzugefügt, der die Aktualisierung der Gewichte glättet.
v_t: Beschleunigung in Richtung des Minimums
beta: Momentum-Faktor (meist um 0.9)
Adaptive Lernraten-Methoden¶
Adagrad:
Passt die Lernrate individuell für jede Modellparameter-Aktualisierung an.
Vorteil: Funktioniert gut für spärliche Daten.
Nachteil: Lernrate kann zu stark abfallen.
RMSprop:
Eine Erweiterung von Adagrad mit gleitendem Durchschnitt der Gradienten.
Funktioniert besonders gut für tiefe neuronale Netze.
Adam-Optimizer (Adaptive Moment Estimation):
Kombiniert die Vorteile von Momentum und RMSprop, d.h. passt eigenständig die Lernrate individuell für jede Modellparameter-Aktualisierung an, ohne dass die Lernrate zu stark abfällt.
Vorteil: Stabile und schnelle Konvergenz, besonders in Deep Learning.
Nachteil: Kann für einige Probleme eine zu hohe Variabilität aufweisen.
Hyperparameter-Tuning – Die richtige Balance finden¶
Neben der Optimierung der Modellparameter selbst müssen wir oft Hyperparameter optimieren (z. B. die Lernrate ( alpha )). Dazu gibt es verschiedene Methoden:
Grid Search:
Testet systematisch alle möglichen Kombinationen von Hyperparametern.
Nachteil: Sehr rechenintensiv.
Random Search:
Wählt zufällige Kombinationen von Hyperparametern aus.
Vorteil: Spart Rechenzeit, oft ähnlich gute Ergebnisse wie Grid Search.
Bayesian Optimization:
Verwendet probabilistische Modelle zur effizienten Auswahl von Hyperparametern.
Vorteil: Schneller als Grid Search bei komplexen Modellen.