Systemübersicht – wie Training, Testing, Inferencing und CI/CD zusammenhängen¶
In diesem Kapitel sprechen wir über die verschiedenen Phasen des Machine Learnings: Training, Test, und Inferenz.
Dies sind die drei zentralen Phasen, die im gesamten Modellierungsprozess eine wichtige Rolle spielen:
Training
Während des Trainingsprozesses lernt das Modell, indem es aus großen Mengen gelabelter Daten Muster erkennt.
Es passt seine Parameter (Gewichte) an, um die Loss Function zu minimieren.
Dieser Prozess erfolgt über wiederholte Forward- und Backwardpropagation.
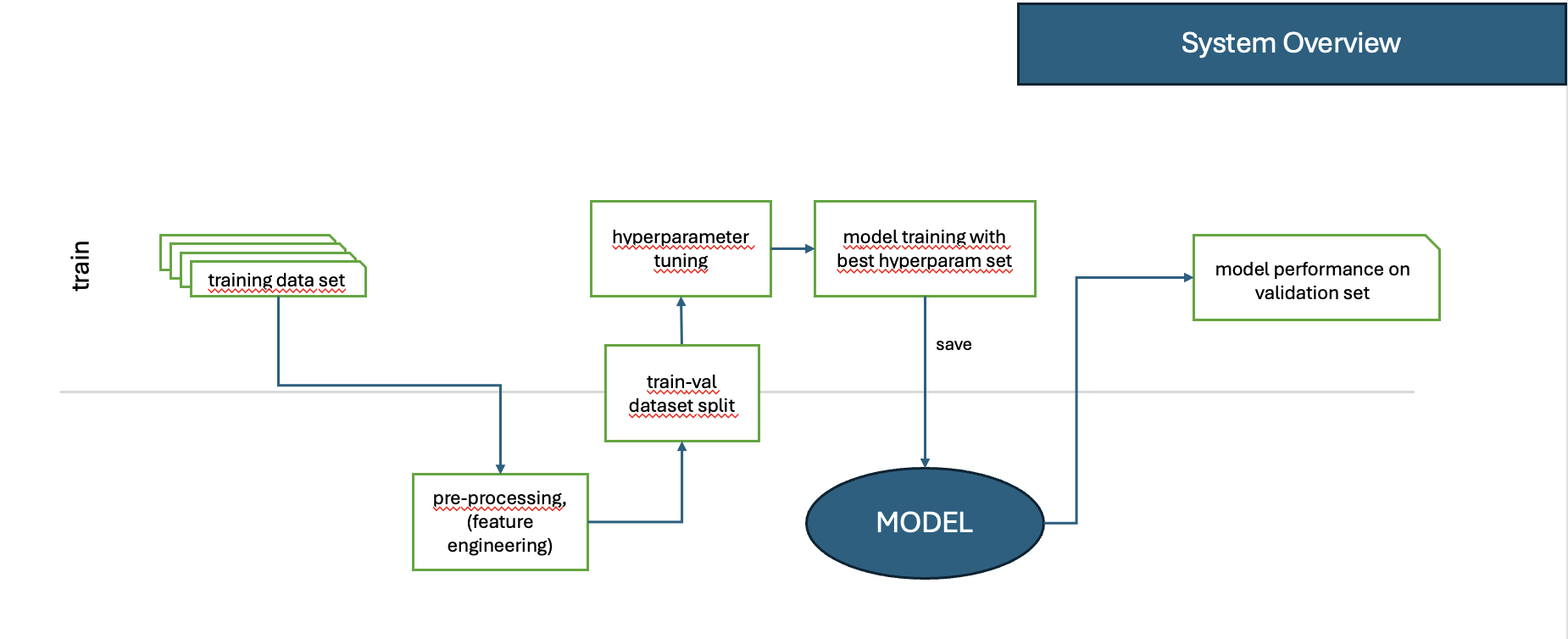
Abbildung 1: Überblick über Training Pipelines.¶
Test:
Nach dem Training wird das Modell auf einem separaten Testdatensatz evaluiert, um seine Generalisierungsfähigkeit zu überprüfen.
Es werden keine Gewichtsaktualisierungen vorgenommen, sondern nur die Vorhersagequalität bewertet.
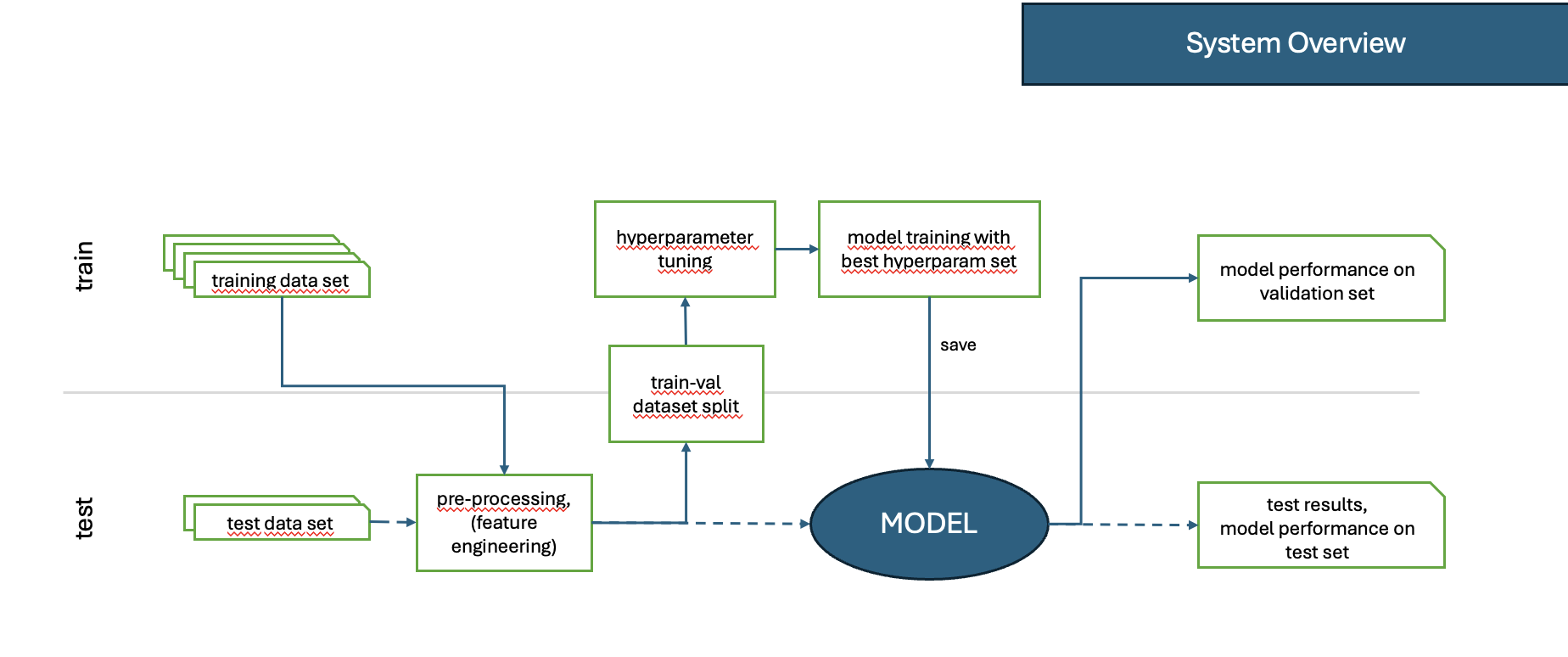
Abbildung 1: Überblick über Training und Test Pipeline.¶
Inference (Vorhersage):
Nach dem erfolgreichen Training und der Evaluierung wird das Modell für echte Daten eingesetzt.
In dieser Phase macht das Modell Vorhersagen auf unbekannten Daten, ohne dass weitere Anpassungen an den Gewichten erfolgen.
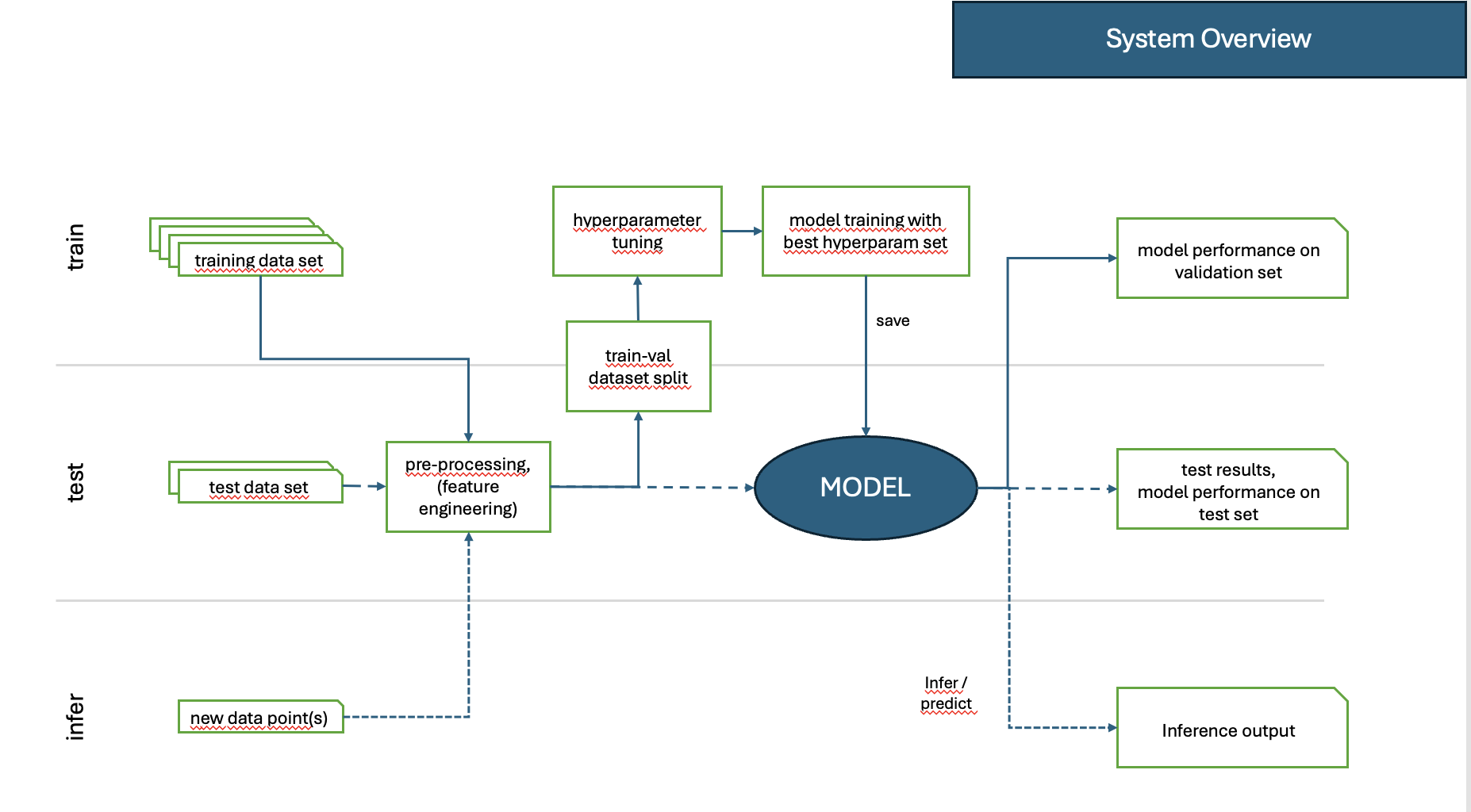
Abbildung 1: Überblick über Training, Test und Inference Pipelines.¶
Diese Unterscheidung ist essenziell, um zu verstehen, wann, wie und womit Modelle trainiert, getestet und produktiv genutzt werden. Der Bedarf an Infrastruktur und Architektur kann zwischen dem Trainings- und Inference-Prozess oft stark unterscheiden, z.B. wird vor allem bei Deep-Learning-Modellen während des Trainings sehr viel Rechenleistung für die Backpropagation verbraucht, während die Inference-Phase ausschließlich Forwardpropagation ausgeführt und somit wesentlich weniger Rechenleistung verbraucht wird.
Modell-Tracking und kontinuierliches Training (CI/CD)
Wenn ein Modell einmal trainiert ist, bleibt es noch lange nicht für immer optimal. Da sich die realen Bedingungen ändern können, ist ein kontinuierliches Monitoring und Modell-Tracking erforderlich:
Vergleich der Inference-Vorhersagen mit echten Ergebnissen: Das Deployment System sollte so aufgesetzt sein, dass es ständig oder regelmäßig trackt, ob das Modell weiterhin akkurate Vorhersagen trifft.
Feedback-Schleifen: Diese realen Daten sollten gesammelt werden, um das Modell regelmäßig mit neuen Daten nachtrainieren zu können.
Automatische Datenaufnahme: Diese neuen „real-world“ Daten sollten nicht händisch, sondern automatisch gesammelt werden und automatisch in das nächste Training einfließen.
Modell-Drift erkennen: Falls sich das Verhalten der Eingabedaten oder Zielvariablen ändert, sollte das Modell aktualisiert werden.
Ein gängiger Ansatz ist Active Learning, bei dem das Modell selbst bestimmt, welche neuen Daten für das Training am wertvollsten sind. Diese können dann mit menschlichem Feedback gelabelt und zur Verbesserung des Modells genutzt werden.
Dieser Prozess ist ein Hauptbestandteil von MLOps (Machine Learning & Operations), das den kompletten ML-Lifecycle rationalisiert - von der Modellentwicklung und -training bis zur Modellbereitstellung und Überwachung.
Ziel hierbei ist es, die Zusammenarbeit und Kommunikation zwischen den verschiedenen Kollaboratoren wie Data Scientist, Machine Learning Ingenieuren und Software-/IT-Ops-Teams zu verbessern, um letztlich die richtige, sichere und stabile Bereitstellung hochwertiger ML-Anwendungen zu beschleunigen.
Somit ist es auch Teil vom allgemeinen CI/CD (Continuous Integration/Continuous Delivery) in der Software-Entwicklung, das der kontinuierlichen Zusammenführung von kleinen Änderungen und Korrekturen, den kurzen Zyklen zwischen Software-Code updates für ein ständig stabiles System auf hoher Qualität dient.
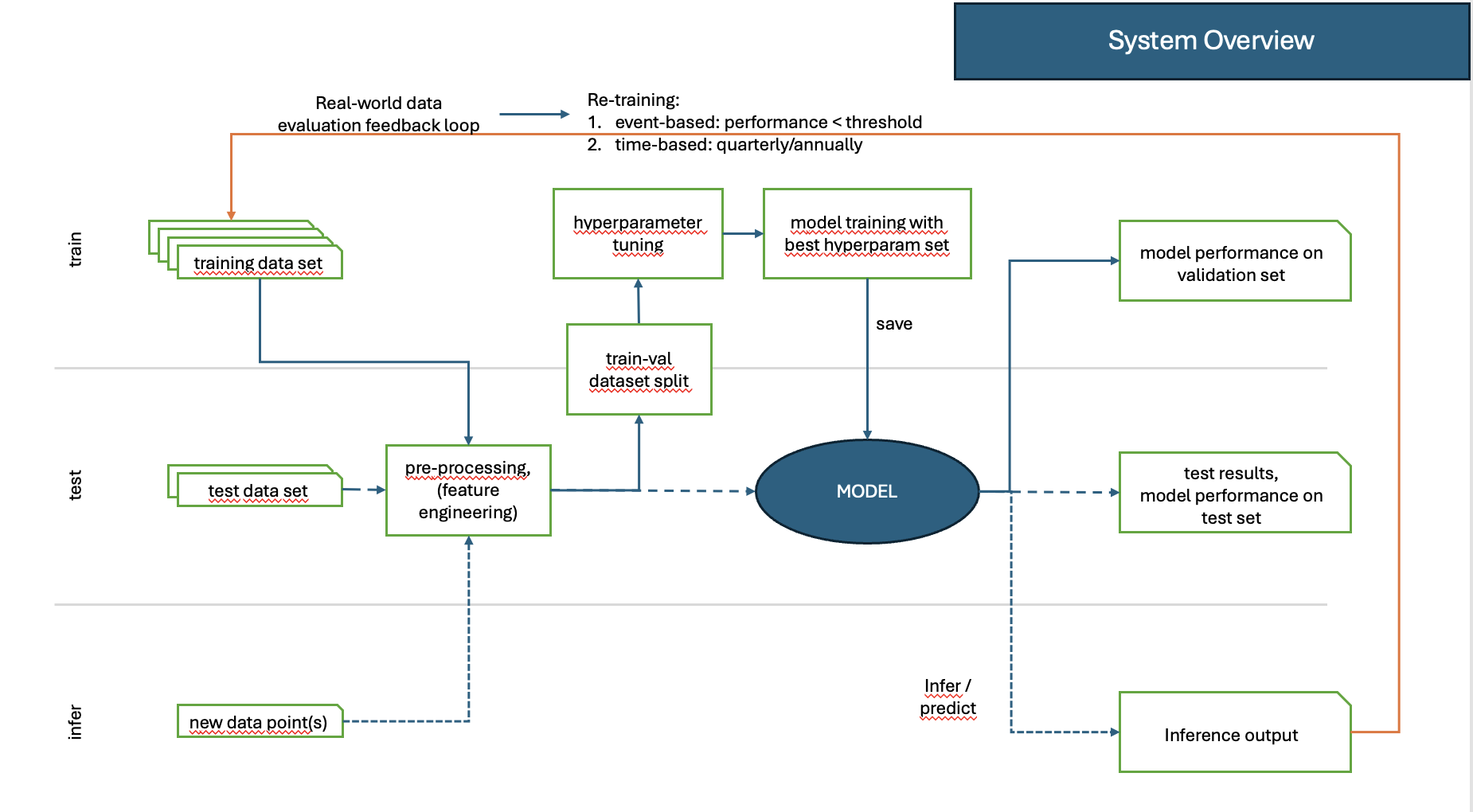
Abbildung 1: Überblick über Training, Test und Inference Pipelines mit Active Learning.¶
Siehe auch