Praxisbeispiel - Telko Vertragskundenabgang-Vorhersage MIT simulierten Kunden-Service-Daten¶
Die Vorhersage der Kundenabwanderung (bei Vertragssituationen) sagt die Wahrscheinlichkeit voraus, dass Kunden die Produkte oder Dienstleistungen eines Unternehmens kündigen. In den meisten Fällen sind Unternehmen mit Stammkunden oder Kunden im Abonnement bestrebt, ihren Kundenstamm zu erhalten. Daher ist es wichtig, die Kunden zu verfolgen, die ihr Abonnement kündigen, und diejenigen, die den Dienst weiter nutzen. Dieser Ansatz setzt voraus, dass das Unternehmen das Verhalten seiner Kunden kennt und versteht und die Eigenschaften, die zu dem Risiko führen, dass der Kunde das Unternehmen verlässt.
Szenario¶
Annahme: Wir sind ein Telekommunikations-Unternehmen, das über historische Daten darüber verfügt, wie seine Kunden mit seinen Dienstleistungen interagiert haben. Das Unternehmen möchte wissen, wie hoch die Wahrscheinlichkeit ist, dass Kunden abwandern, damit es gezielte Marketingkampagnen starten kann.
Datensatz¶
Wir nutzen den Kaggle-Datensatz als die Baseline der Kundeninformationen: https://www.kaggle.com/datasets/blastchar/telco-customer-churn
Wir nutzen einen selbst simulierten Datensatz bzgl. Kunden-Service, das vorher in diesem Folder abgespeichert wurde: kunden_service.csv
[1]:
import sys
# !{sys.executable} -m pip install kagglehub
# !{sys.executable} -m pip install @
# !{sys.executable} -m pip install missingno
[2]:
import kagglehub
[3]:
import pandas as pd
import numpy as np
# import missingno as msno
import matplotlib.pyplot as plt
import seaborn as sns
# import plotly.express as px
# import plotly.graph_objects as go
# from plotly.subplots import make_subplots
import warnings
pd.set_option("display.max_columns", None)
warnings.filterwarnings("ignore")
[4]:
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.metrics import roc_curve
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
# from xgboost import XGBClassifier
# from catboost import CatBoostClassifier
[5]:
# Download data from Kaggle
path = kagglehub.dataset_download("blastchar/telco-customer-churn")
print("Path to files:", path)
Path to files: /Users/veit/.cache/kagglehub/datasets/blastchar/telco-customer-churn/versions/1
[6]:
path_file = "~/.cache/kagglehub/datasets/blastchar/telco-customer-churn/versions/1/WA_Fn-UseC_-Telco-Customer-Churn.csv"
print(path_file)
~/.cache/kagglehub/datasets/blastchar/telco-customer-churn/versions/1/WA_Fn-UseC_-Telco-Customer-Churn.csv
Daten laden¶
[7]:
df_ori = pd.read_csv(path_file)
df_ori
[7]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | Yes | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | No | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | Yes | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | No | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | No | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7038 | 6840-RESVB | Male | 0 | Yes | Yes | 24 | Yes | Yes | DSL | Yes | No | Yes | Yes | Yes | Yes | One year | Yes | Mailed check | 84.80 | 1990.5 | No |
| 7039 | 2234-XADUH | Female | 0 | Yes | Yes | 72 | Yes | Yes | Fiber optic | No | Yes | Yes | No | Yes | Yes | One year | Yes | Credit card (automatic) | 103.20 | 7362.9 | No |
| 7040 | 4801-JZAZL | Female | 0 | Yes | Yes | 11 | No | No phone service | DSL | Yes | No | No | No | No | No | Month-to-month | Yes | Electronic check | 29.60 | 346.45 | No |
| 7041 | 8361-LTMKD | Male | 1 | Yes | No | 4 | Yes | Yes | Fiber optic | No | No | No | No | No | No | Month-to-month | Yes | Mailed check | 74.40 | 306.6 | Yes |
| 7042 | 3186-AJIEK | Male | 0 | No | No | 66 | Yes | No | Fiber optic | Yes | No | Yes | Yes | Yes | Yes | Two year | Yes | Bank transfer (automatic) | 105.65 | 6844.5 | No |
7043 rows × 21 columns
[8]:
path_kunden_service_log = "kunden_service.csv"
df_service = pd.read_csv(path_kunden_service_log)
df_service
[8]:
| ticket_id | customer_id | time_request | time_reply | channel | request | reply | solved | original_request | original_ticket_id | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG_T1 | 7590-VHVEG | 2024-12-23 00:00:00 | 2024-12-23 14:28:40 | On-site | Internet funktioniert nicht | Ticket geschlossen | True | True | NaN |
| 1 | 7590-VHVEG_T1 | 7590-VHVEG | 2024-12-23 14:28:40 | 2024-12-23 20:20:22 | Hotline | Internet funktioniert nicht | Anfrage wird bearbeitet | False | False | 7590-VHVEG_T1 |
| 2 | 5575-GNVDE_T1 | 5575-GNVDE | 2023-09-03 00:00:00 | 2023-09-03 12:48:24 | Internet funktioniert nicht | Problem gelöst | True | True | NaN | |
| 3 | 5575-GNVDE_T1 | 5575-GNVDE | 2023-09-04 12:48:24 | 2023-09-05 08:04:13 | Social Media | Frage zum Vertrag | Weitere Informationen benötigt | False | False | 5575-GNVDE_T1 |
| 4 | 5575-GNVDE_T2 | 5575-GNVDE | 2024-12-16 00:00:00 | 2024-12-17 20:29:09 | On-site | Internet funktioniert nicht | Weitere Informationen benötigt | False | True | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 28153 | 6840-RESVB_T1 | 6840-RESVB | 2024-03-18 20:03:20 | 2024-03-18 23:24:42 | Beschwerde über Kundenservice | Ticket geschlossen | True | False | 6840-RESVB_T1 | |
| 28154 | 4801-JZAZL_T1 | 4801-JZAZL | 2024-08-11 00:00:00 | 2024-08-11 11:26:24 | Hotline | Problem mit Rechnung | Ticket geschlossen | True | True | NaN |
| 28155 | 4801-JZAZL_T1 | 4801-JZAZL | 2024-08-11 11:26:24 | 2024-08-12 13:54:33 | Problem mit Rechnung | Anfrage wird bearbeitet | False | False | 4801-JZAZL_T1 | |
| 28156 | 8361-LTMKD_T1 | 8361-LTMKD | 2024-10-16 00:00:00 | 2024-10-16 17:35:16 | On-site | Problem mit Rechnung | Problem gelöst | True | True | NaN |
| 28157 | 8361-LTMKD_T1 | 8361-LTMKD | 2024-10-16 17:35:16 | 2024-10-16 20:38:36 | Hotline | Beschwerde über Kundenservice | Weitere Informationen benötigt | False | False | 8361-LTMKD_T1 |
28158 rows × 10 columns
Daten Manipulation / Bereinigung¶
Original Kunden-Datensatz¶
[9]:
df_ori["TotalCharges"] = pd.to_numeric(df_ori.TotalCharges, errors="coerce")
[10]:
df_ori.drop(labels=df_ori[df_ori["tenure"] == 0].index, axis=0, inplace=True)
df_ori.head()
[10]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | Yes | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | No | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.50 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | Yes | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | No | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | No | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
[11]:
df_ori.reset_index(inplace=True)
df_ori.head()
[11]:
| index | customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | Yes | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | No | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.50 | No |
| 2 | 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | Yes | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | No | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | No | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
[12]:
if "index" in df_ori:
df_ori.drop("index", axis=1, inplace=True)
df_ori.head()
[12]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | Yes | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | No | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.50 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | Yes | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | No | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | No | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
Kunden-IDs?¶
Achtung! Die customerIDs können jetzt nicht so schnell verworfen werden! Die brauchen wir, um die beiden Tabellen miteinander zu verknüpfen!
Kategorische Spalten umwandeln¶
Um die kategorischen Spalten richtig in numerische Spalten umzuwandeln, lass uns sie genauer anschauen und identifizieren, was sich hinter den Strings wirklich verbirgt.
DatenAnalyse:¶
binary: gender,
boolean: SeniorCitizen, Partner, Dependents, PhoneService, OnlineSecurity, OnlineBackup, DeviceProtection, TechSupport, StreamingTV, StreamingMovies, PaperlessBilling
categorical: MultipleLines, InternetService, Contract, PaymentMethod
numeric: tenure, MonthlyCharges, TotalCharges
Unterteile die Columns in 3 Kategorien: Standardisierung, Ordinal-Encoding and One-Hot-Encoding¶
binary (direkte Umwandlung zu 0-1): gender
boolean (direkte Umwandlung zu 0-1): SeniorCitizen, Partner, Dependents, PhoneService, OnlineSecurity, OnlineBackup, DeviceProtection, TechSupport, StreamingTV, StreamingMovies, PaperlessBilling
categorical (One-Hot oder Frequency Encoding etc): MultipleLines, InternetService, Contract, PaymentMethod
numeric: tenure, MonthlyCharges, TotalCharges
[13]:
cols_ori_binary = ["gender"]
cols_ori_boolean = ["SeniorCitizen", "Partner", "Dependents", "PhoneService", "OnlineSecurity", "OnlineBackup",
"DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies", "PaperlessBilling"]
cols_ori_cat = ["MultipleLines", "InternetService", "Contract", "PaymentMethod"]
cols_ori_numeric = ["tenure", "MonthlyCharges", "TotalCharges"]
[14]:
# Mapping von "Female" zu 1 und "Male" zu 0
df_ori["gender"] = df_ori["gender"].map({"Female": 1, "Male": 0})
df_ori["gender"]
[14]:
0 1
1 0
2 0
3 0
4 1
..
7027 0
7028 1
7029 1
7030 0
7031 0
Name: gender, Length: 7032, dtype: int64
[15]:
for col in cols_ori_boolean:
df_ori[col] = df_ori[col].eq("Yes").mul(1)
df_ori[cols_ori_boolean]
[15]:
| SeniorCitizen | Partner | Dependents | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7027 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| 7028 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
| 7029 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 7030 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 7031 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
7032 rows × 11 columns
[16]:
# One-Hot-Encoding für die drei kategorischen Spalten
df_onehot_encoded = pd.get_dummies(df_ori, columns=cols_ori_cat) # dtype=int
print(df_onehot_encoded.shape)
df_onehot_encoded
(7032, 30)
[16]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | No | False | True | False | True | False | False | True | False | False | False | False | True | False |
| 1 | 5575-GNVDE | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | No | True | False | False | True | False | False | False | True | False | False | False | False | True |
| 2 | 3668-QPYBK | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | Yes | True | False | False | True | False | False | True | False | False | False | False | False | True |
| 3 | 7795-CFOCW | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | No | False | True | False | True | False | False | False | True | False | True | False | False | False |
| 4 | 9237-HQITU | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | Yes | True | False | False | False | True | False | True | False | False | False | False | True | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7027 | 6840-RESVB | 0 | 0 | 1 | 1 | 24 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 84.80 | 1990.50 | No | False | False | True | True | False | False | False | True | False | False | False | False | True |
| 7028 | 2234-XADUH | 1 | 0 | 1 | 1 | 72 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 103.20 | 7362.90 | No | False | False | True | False | True | False | False | True | False | False | True | False | False |
| 7029 | 4801-JZAZL | 1 | 0 | 1 | 1 | 11 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 29.60 | 346.45 | No | False | True | False | True | False | False | True | False | False | False | False | True | False |
| 7030 | 8361-LTMKD | 0 | 0 | 1 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 74.40 | 306.60 | Yes | False | False | True | False | True | False | True | False | False | False | False | False | True |
| 7031 | 3186-AJIEK | 0 | 0 | 0 | 0 | 66 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 105.65 | 6844.50 | No | True | False | False | False | True | False | False | False | True | True | False | False | False |
7032 rows × 30 columns
[17]:
df_onehot_encoded.columns.tolist()
[17]:
['customerID',
'gender',
'SeniorCitizen',
'Partner',
'Dependents',
'tenure',
'PhoneService',
'OnlineSecurity',
'OnlineBackup',
'DeviceProtection',
'TechSupport',
'StreamingTV',
'StreamingMovies',
'PaperlessBilling',
'MonthlyCharges',
'TotalCharges',
'Churn',
'MultipleLines_No',
'MultipleLines_No phone service',
'MultipleLines_Yes',
'InternetService_DSL',
'InternetService_Fiber optic',
'InternetService_No',
'Contract_Month-to-month',
'Contract_One year',
'Contract_Two year',
'PaymentMethod_Bank transfer (automatic)',
'PaymentMethod_Credit card (automatic)',
'PaymentMethod_Electronic check',
'PaymentMethod_Mailed check']
[18]:
index_label = df_onehot_encoded.columns.tolist().index("Churn")
print(df_ori.columns.tolist()[index_label])
cols_onehot_encoded = df_onehot_encoded.columns.tolist()[index_label+1:]
print(len(cols_onehot_encoded))
cols_onehot_encoded
PaperlessBilling
13
[18]:
['MultipleLines_No',
'MultipleLines_No phone service',
'MultipleLines_Yes',
'InternetService_DSL',
'InternetService_Fiber optic',
'InternetService_No',
'Contract_Month-to-month',
'Contract_One year',
'Contract_Two year',
'PaymentMethod_Bank transfer (automatic)',
'PaymentMethod_Credit card (automatic)',
'PaymentMethod_Electronic check',
'PaymentMethod_Mailed check']
[19]:
for col in cols_onehot_encoded:
df_onehot_encoded[col] = df_onehot_encoded[col].eq("Yes").mul(1)
[20]:
df_onehot_encoded
[20]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 5575-GNVDE | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 3668-QPYBK | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 7795-CFOCW | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 9237-HQITU | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7027 | 6840-RESVB | 0 | 0 | 1 | 1 | 24 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 84.80 | 1990.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7028 | 2234-XADUH | 1 | 0 | 1 | 1 | 72 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 103.20 | 7362.90 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7029 | 4801-JZAZL | 1 | 0 | 1 | 1 | 11 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 29.60 | 346.45 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7030 | 8361-LTMKD | 0 | 0 | 1 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 74.40 | 306.60 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7031 | 3186-AJIEK | 0 | 0 | 0 | 0 | 66 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 105.65 | 6844.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
7032 rows × 30 columns
Kunden-Service Datensatz¶
Würden wir einen echten Kunden-Service Datensatz erhalten, müssten wir ihn genau so aufmerksam kontrollieren und checken, ob es missing fields gibt, etc.
[21]:
df_service.head()
[21]:
| ticket_id | customer_id | time_request | time_reply | channel | request | reply | solved | original_request | original_ticket_id | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG_T1 | 7590-VHVEG | 2024-12-23 00:00:00 | 2024-12-23 14:28:40 | On-site | Internet funktioniert nicht | Ticket geschlossen | True | True | NaN |
| 1 | 7590-VHVEG_T1 | 7590-VHVEG | 2024-12-23 14:28:40 | 2024-12-23 20:20:22 | Hotline | Internet funktioniert nicht | Anfrage wird bearbeitet | False | False | 7590-VHVEG_T1 |
| 2 | 5575-GNVDE_T1 | 5575-GNVDE | 2023-09-03 00:00:00 | 2023-09-03 12:48:24 | Internet funktioniert nicht | Problem gelöst | True | True | NaN | |
| 3 | 5575-GNVDE_T1 | 5575-GNVDE | 2023-09-04 12:48:24 | 2023-09-05 08:04:13 | Social Media | Frage zum Vertrag | Weitere Informationen benötigt | False | False | 5575-GNVDE_T1 |
| 4 | 5575-GNVDE_T2 | 5575-GNVDE | 2024-12-16 00:00:00 | 2024-12-17 20:29:09 | On-site | Internet funktioniert nicht | Weitere Informationen benötigt | False | True | NaN |
[22]:
df_service.dtypes
[22]:
ticket_id str
customer_id str
time_request str
time_reply str
channel str
request str
reply str
solved bool
original_request bool
original_ticket_id str
dtype: object
[23]:
# Die datetime-Spalten müssen in deren Typ angepasst werden, alles andere kann in deren Original-Form bleiben (string)
df_service["time_request"] = pd.to_datetime(df_service["time_request"], errors="coerce")
df_service["time_reply"] = pd.to_datetime(df_service["time_reply"], errors="coerce")
df_service.dtypes
[23]:
ticket_id str
customer_id str
time_request datetime64[us]
time_reply datetime64[us]
channel str
request str
reply str
solved bool
original_request bool
original_ticket_id str
dtype: object
[24]:
df_service.isnull().sum()
[24]:
ticket_id 0
customer_id 0
time_request 0
time_reply 0
channel 0
request 0
reply 0
solved 0
original_request 0
original_ticket_id 14140
dtype: int64
Die große Anzahl an null-Werten in der original_ticket_id-Spalte sind in diesem Datensatz kein Fehler, sondern einleuchtend in der Logik (das wissen wir - haben wir selbst kreiert).
Daher werden hier keine Daten gelöscht, sondern wir würden die leeren Datenfelder extrapolieren.
Da es sich in dieser Spalte um alphanumerischen IDs handelt, ist die naheliegendste Lösung einen leeren String zu machen. Es ist keine Option, sie bei null zu belassen, da die Funktionen in den follow-up Schritten eine vollständig gefüllte Spalte benötigen.
[25]:
df_service["original_ticket_id"].fillna("", inplace=True)
[25]:
0
1 7590-VHVEG_T1
2
3 5575-GNVDE_T1
4
...
28153 6840-RESVB_T1
28154
28155 4801-JZAZL_T1
28156
28157 8361-LTMKD_T1
Name: original_ticket_id, Length: 28158, dtype: str
[26]:
df_service.isnull().sum()
[26]:
ticket_id 0
customer_id 0
time_request 0
time_reply 0
channel 0
request 0
reply 0
solved 0
original_request 0
original_ticket_id 14140
dtype: int64
[27]:
# Dann wollen wir checken, ob es irgendein Datum gibt, das nach dem Stichtag ist
df_service["time_request"].max()
[27]:
Timestamp('2024-12-31 23:58:29')
[28]:
df_service["time_reply"].max()
[28]:
Timestamp('2024-12-31 23:59:39')
[29]:
# Zudem wollen wir kontrollieren, ob es Fehler in der Logik gibt, z.b. time_reply vor time_request
df_service[df_service["time_reply"]<df_service["time_request"]]
[29]:
| ticket_id | customer_id | time_request | time_reply | channel | request | reply | solved | original_request | original_ticket_id |
|---|
[30]:
df_service.head()
[30]:
| ticket_id | customer_id | time_request | time_reply | channel | request | reply | solved | original_request | original_ticket_id | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG_T1 | 7590-VHVEG | 2024-12-23 00:00:00 | 2024-12-23 14:28:40 | On-site | Internet funktioniert nicht | Ticket geschlossen | True | True | NaN |
| 1 | 7590-VHVEG_T1 | 7590-VHVEG | 2024-12-23 14:28:40 | 2024-12-23 20:20:22 | Hotline | Internet funktioniert nicht | Anfrage wird bearbeitet | False | False | 7590-VHVEG_T1 |
| 2 | 5575-GNVDE_T1 | 5575-GNVDE | 2023-09-03 00:00:00 | 2023-09-03 12:48:24 | Internet funktioniert nicht | Problem gelöst | True | True | NaN | |
| 3 | 5575-GNVDE_T1 | 5575-GNVDE | 2023-09-04 12:48:24 | 2023-09-05 08:04:13 | Social Media | Frage zum Vertrag | Weitere Informationen benötigt | False | False | 5575-GNVDE_T1 |
| 4 | 5575-GNVDE_T2 | 5575-GNVDE | 2024-12-16 00:00:00 | 2024-12-17 20:29:09 | On-site | Internet funktioniert nicht | Weitere Informationen benötigt | False | True | NaN |
EDA - Explorative Data Analysis (Daten Exploration)¶
Die EDA (Explorative Daten Analysis) des df_ori lassen wir in diesem Notebook aus, da wir es im letzten Notebook ausgiebig besprochen haben
[31]:
df_service.value_counts("channel", ascending=False)
[31]:
channel
On-site 5744
Chat 5645
Social Media 5625
Hotline 5593
Email 5551
Name: count, dtype: int64
[32]:
df_service.value_counts("request")
[32]:
request
Internet funktioniert nicht 5769
Problem mit Rechnung 5675
Frage zum Vertrag 5597
Beschwerde über Kundenservice 5560
Technische Störung 5557
Name: count, dtype: int64
[33]:
df_service[["request", "reply"]].groupby(["request"]).value_counts(ascending=False)
[33]:
request reply
Beschwerde über Kundenservice Weitere Informationen benötigt 1401
Anfrage wird bearbeitet 1390
Ticket geschlossen 1387
Problem gelöst 1382
Frage zum Vertrag Ticket geschlossen 1429
Weitere Informationen benötigt 1420
Anfrage wird bearbeitet 1407
Problem gelöst 1341
Internet funktioniert nicht Problem gelöst 1477
Anfrage wird bearbeitet 1476
Ticket geschlossen 1417
Weitere Informationen benötigt 1399
Problem mit Rechnung Ticket geschlossen 1464
Weitere Informationen benötigt 1450
Problem gelöst 1401
Anfrage wird bearbeitet 1360
Technische Störung Weitere Informationen benötigt 1411
Anfrage wird bearbeitet 1409
Problem gelöst 1409
Ticket geschlossen 1328
Name: count, dtype: int64
[34]:
df_service.value_counts("solved", ascending=False)
[34]:
solved
False 14123
True 14035
Name: count, dtype: int64
[35]:
df_service[["request","solved"]].groupby(["request"]).value_counts(ascending=False)
[35]:
request solved
Beschwerde über Kundenservice False 2791
True 2769
Frage zum Vertrag False 2827
True 2770
Internet funktioniert nicht True 2894
False 2875
Problem mit Rechnung True 2865
False 2810
Technische Störung False 2820
True 2737
Name: count, dtype: int64
[36]:
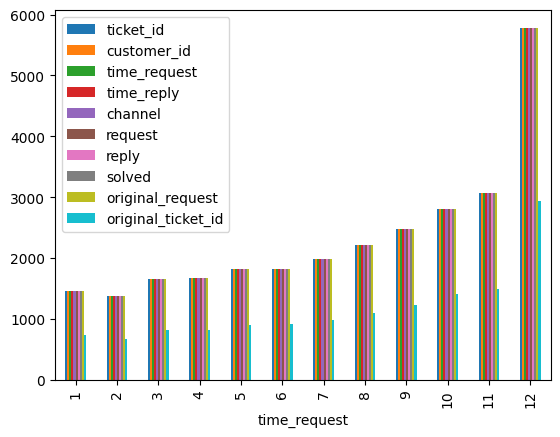
df_service.groupby(df_service["time_request"].dt.month).count().plot(kind="bar")
[36]:
<Axes: xlabel='time_request'>
[37]:
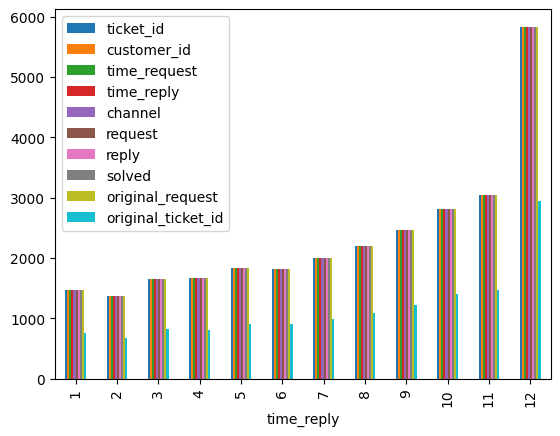
df_service.groupby(df_service["time_reply"].dt.month).count().plot(kind="bar")
[37]:
<Axes: xlabel='time_reply'>
Feature Engineering¶
[38]:
# Definiere den Stichtag für die Features
stichtag = pd.to_datetime("2024-12-31")
# Wir werden viele verschiedene Features erstellen, diese werden erst gesammelt und später zum DataFrame umgewandelt
dict_features = {}
Feature-Gruppe 1: Anzahl der Requests im letzten Monat¶
[39]:
# Definiere den Cutoff für die letzten 1 Monat
cutoff_1m = stichtag - pd.DateOffset(months=1)
# Filtere die Anfragen, die ab dem Cutoff bis zum Stichtag erfolgen
recent_requests = df_service[df_service["time_request"] >= cutoff_1m]
# Zähle pro Kunde die Anzahl der Requests
num_request_last_1m = recent_requests.groupby("customer_id").size().rename("num_request_last_1_month")
# Ausgabe: Beispieldatensatz
print(num_request_last_1m.head())
customer_id
0013-EXCHZ 6
0015-UOCOJ 1
0021-IKXGC 13
0023-HGHWL 3
0030-FNXPP 3
Name: num_request_last_1_month, dtype: int64
[40]:
# Anzahl Requests in den letzten 6, 9 etc Monaten
months_interest = [1, 3, 6, 12]
for mon in months_interest:
# Definiere den Cutoff für die letzten 3 Monate
cutoff = stichtag - pd.DateOffset(months=mon)
# Filtere die Anfragen, die ab dem Cutoff bis zum Stichtag erfolgen
recent_requests = df_service[df_service["time_request"] >= cutoff]
# Zähle pro Kunde die Anzahl der Requests
col_new = "num_request_last_"+str(mon)+"_months"
num_request_period = recent_requests.groupby("customer_id").size().rename(col_new)
# Füge das Ergebnis dem features_df hinzu. Da die customer_ids als Index genutzt werden, eignet sich join()
# df_features = df_features.join(num_request_period, how='left')
dict_features[col_new] = num_request_period
print(dict_features.keys())
dict_features
dict_keys(['num_request_last_1_months', 'num_request_last_3_months', 'num_request_last_6_months', 'num_request_last_12_months'])
[40]:
{'num_request_last_1_months': customer_id
0013-EXCHZ 6
0015-UOCOJ 1
0021-IKXGC 13
0023-HGHWL 3
0030-FNXPP 3
..
9972-NKTFD 1
9975-SKRNR 3
9985-MWVIX 3
9986-BONCE 3
9992-UJOEL 1
Name: num_request_last_1_months, Length: 1365, dtype: int64,
'num_request_last_3_months': customer_id
0003-MKNFE 3
0004-TLHLJ 3
0013-EXCHZ 9
0015-UOCOJ 1
0018-NYROU 1
..
9986-BONCE 9
9987-LUTYD 3
9992-RRAMN 3
9992-UJOEL 1
9995-HOTOH 2
Name: num_request_last_3_months, Length: 2338, dtype: int64,
'num_request_last_6_months': customer_id
0002-ORFBO 1
0003-MKNFE 4
0004-TLHLJ 3
0013-EXCHZ 9
0013-MHZWF 4
..
9986-BONCE 11
9987-LUTYD 8
9992-RRAMN 6
9992-UJOEL 1
9995-HOTOH 2
Name: num_request_last_6_months, Length: 3191, dtype: int64,
'num_request_last_12_months': customer_id
0002-ORFBO 3
0003-MKNFE 4
0004-TLHLJ 3
0011-IGKFF 1
0013-EXCHZ 9
..
9986-BONCE 11
9987-LUTYD 8
9992-RRAMN 6
9992-UJOEL 1
9995-HOTOH 2
Name: num_request_last_12_months, Length: 4198, dtype: int64}
Feature-Gruppe 2 & 3: Zeit bis Lösung und Anzahl der Thread-Iterationen pro Ticket¶
Hierfür müssen wir zuerst nach Ticket-ID gruppieren, um pro Ticket den Zeitraum von der ursprünglichen Anfrage bis zur ersten als gelöst markierten Antwort zu bestimmen.
Falls ein Ticket nie als gelöst markiert wurde, ignorieren wir es in der Berechnung.
[41]:
def compute_ticket_metrics(ticket):
"""
Für ein Ticket (alle Interaktionen mit gleicher ticket_id):
- Ermittle die Zeitdifferenz (in Tagen) zwischen der ersten Anfrage und der ersten Antwort, die das Ticket als gelöst markiert.
- Bestimme die Anzahl der Interaktionen (Thread-Iterationen) bis zur Lösung.
"""
ticket_sorted = ticket.sort_values("time_request")
# Die erste Anfrage (wir gehen davon aus, dass die erste Zeile die originale Anfrage ist)
orig_time = ticket_sorted.iloc[0]["time_request"]
# Finde die erste Interaktion, bei der solved True ist
solved_interactions = ticket_sorted[ticket_sorted["solved"] == True]
if len(solved_interactions) > 0:
solved_time = solved_interactions.iloc[0]["time_reply"]
days_to_solution = (solved_time - orig_time).days
# Ermittle die Position (Index im sortierten Ticket), beginnend bei 1
thread_count = ticket_sorted.reset_index().index[ticket_sorted.reset_index()["solved"] == True][0] + 1
else:
days_to_solution = np.nan
thread_count = np.nan
return pd.Series({"days_to_solution": days_to_solution, "thread_count": thread_count})
[42]:
# Berechne Ticket-Metriken pro Ticket
ticket_metrics = df_service.groupby("ticket_id").apply(compute_ticket_metrics)
ticket_metrics.head()
[42]:
| days_to_solution | thread_count | |
|---|---|---|
| ticket_id | ||
| 0002-ORFBO_T1 | 0.0 | 1.0 |
| 0003-MKNFE_T1 | NaN | NaN |
| 0003-MKNFE_T2 | 0.0 | 1.0 |
| 0004-TLHLJ_T1 | 0.0 | 1.0 |
| 0011-IGKFF_T1 | NaN | NaN |
[43]:
df_service[df_service["ticket_id"]=="0003-MKNFE_T1"]
[43]:
| ticket_id | customer_id | time_request | time_reply | channel | request | reply | solved | original_request | original_ticket_id | |
|---|---|---|---|---|---|---|---|---|---|---|
| 13706 | 0003-MKNFE_T1 | 0003-MKNFE | 2024-08-08 | 2024-08-09 11:28:34 | On-site | Beschwerde über Kundenservice | Anfrage wird bearbeitet | False | True | NaN |
[44]:
# Füge die customer_id (die für alle Interaktionen in einem Ticket gleich ist) hinzu
ticket_customer = df_service.groupby("ticket_id")["customer_id"].first().to_frame()
ticket_metrics = ticket_metrics.merge(ticket_customer, left_index=True, right_index=True)
ticket_metrics
[44]:
| days_to_solution | thread_count | customer_id | |
|---|---|---|---|
| ticket_id | |||
| 0002-ORFBO_T1 | 0.0 | 1.0 | 0002-ORFBO |
| 0003-MKNFE_T1 | NaN | NaN | 0003-MKNFE |
| 0003-MKNFE_T2 | 0.0 | 1.0 | 0003-MKNFE |
| 0004-TLHLJ_T1 | 0.0 | 1.0 | 0004-TLHLJ |
| 0011-IGKFF_T1 | NaN | NaN | 0011-IGKFF |
| ... | ... | ... | ... |
| 9992-RRAMN_T3 | 1.0 | 1.0 | 9992-RRAMN |
| 9992-UJOEL_T1 | NaN | NaN | 9992-UJOEL |
| 9993-LHIEB_T1 | 1.0 | 1.0 | 9993-LHIEB |
| 9995-HOTOH_T1 | 1.0 | 2.0 | 9995-HOTOH |
| 9995-HOTOH_T2 | 1.0 | 1.0 | 9995-HOTOH |
14140 rows × 3 columns
[45]:
# Aggregiere pro Kunde (nur Tickets, die gelöst wurden)
avg_days_till_solution = ticket_metrics.groupby("customer_id")["days_to_solution"].mean().rename("avg_days_till_solution")
avg_thread_till_solution = ticket_metrics.groupby("customer_id")["thread_count"].mean().rename("avg_thread_till_solution")
print(avg_days_till_solution.head())
print(avg_thread_till_solution.head())
customer_id
0002-ORFBO 0.0
0003-MKNFE 0.0
0004-TLHLJ 0.0
0011-IGKFF NaN
0013-EXCHZ 1.0
Name: avg_days_till_solution, dtype: float64
customer_id
0002-ORFBO 1.00
0003-MKNFE 1.00
0004-TLHLJ 1.00
0011-IGKFF NaN
0013-EXCHZ 1.25
Name: avg_thread_till_solution, dtype: float64
[46]:
dict_features["avg_num_days_till_solution"] = avg_days_till_solution
dict_features["avg_num_thread_till_solution"] = avg_thread_till_solution
[47]:
dict_features.keys()
[47]:
dict_keys(['num_request_last_1_months', 'num_request_last_3_months', 'num_request_last_6_months', 'num_request_last_12_months', 'avg_num_days_till_solution', 'avg_num_thread_till_solution'])
Feature-Gruppe 4 & 5: Zuletzt benutzter Kanal und am häufigsten genutzter Kanal in den letzten 6 Monaten¶
[48]:
# Last channel used: Finde pro Kunde die letzte Interaktion (Sortierung nach time_request)
last_channel = df_service.sort_values("time_request").groupby("customer_id").last()["channel"].rename("last_channel_used")
# den meist genutzten Channel in letzten 6 Monaten
# zuerst den Zeitraum auf die letzten 6 Monate eingrenzen
cutoff_6m = stichtag - pd.DateOffset(months=6)
channels_last_6m = df_service[df_service["time_request"] >= cutoff_6m]
# Bestimme pro Kunde den am häufigsten auftretenden Kanal in diesem Zeitraum. Falls es mehrere Modi gibt, nimm den ersten.
channel_most_used_last6mo = channels_last_6m.groupby("customer_id")["channel"].agg(lambda x: x.mode().iloc[0] if not x.mode().empty else np.nan)\
.rename("channel_used_most_last_6_months")
print(last_channel.head())
print(channel_most_used_last6mo.head())
customer_id
0002-ORFBO Hotline
0003-MKNFE Social Media
0004-TLHLJ Social Media
0011-IGKFF Social Media
0013-EXCHZ Email
Name: last_channel_used, dtype: str
customer_id
0002-ORFBO Hotline
0003-MKNFE Email
0004-TLHLJ Chat
0013-EXCHZ Chat
0013-MHZWF On-site
Name: channel_used_most_last_6_months, dtype: str
[49]:
dict_features["last_channel"] = last_channel
dict_features["channel_most_used_last6mo"] = channel_most_used_last6mo
[50]:
dict_features.keys()
[50]:
dict_keys(['num_request_last_1_months', 'num_request_last_3_months', 'num_request_last_6_months', 'num_request_last_12_months', 'avg_num_days_till_solution', 'avg_num_thread_till_solution', 'last_channel', 'channel_most_used_last6mo'])
Feature-Gruppe 5: Weitere Features – Gesamtzahl Tickets, Interaktionen, durchschnittliche Reply-Zeit und textbasierte Features¶
[51]:
# Gesamtzahl der Tickets pro Kunde
total_tickets = df_service.groupby("customer_id")["ticket_id"].nunique().rename("total_tickets")
# Gesamtzahl der Interaktionen pro Kunde
total_interactions = df_service.groupby("customer_id").size().rename("total_interactions")
# Durchschnittliche Reply-Verzögerung (in Stunden) pro Interaktion
df_service["reply_delay_hours"] = (df_service["time_reply"] - df_service["time_request"]).dt.total_seconds() / 3600
avg_reply_delay = df_service.groupby("customer_id")["reply_delay_hours"].mean().rename("avg_reply_delay_hours")
# Textbasierte Features:
# Zähle, wie oft im Request-Text Begriffe wie "Problem" oder "Beschwerde" auftauchen
df_service["is_complaint"] = df_service["request"].str.contains("Problem|Beschwerde", case=False, regex=True)
num_complaint_requests = df_service.groupby("customer_id")["is_complaint"].sum().rename("num_complaint_requests")
print(total_tickets.head())
print(total_interactions.head())
print(avg_reply_delay.head())
print(num_complaint_requests.head())
customer_id
0002-ORFBO 1
0003-MKNFE 2
0004-TLHLJ 1
0011-IGKFF 2
0013-EXCHZ 5
Name: total_tickets, dtype: int64
customer_id
0002-ORFBO 3
0003-MKNFE 4
0004-TLHLJ 3
0011-IGKFF 3
0013-EXCHZ 9
Name: total_interactions, dtype: int64
customer_id
0002-ORFBO 19.058148
0003-MKNFE 22.865833
0004-TLHLJ 7.966481
0011-IGKFF 11.924352
0013-EXCHZ 23.818210
Name: avg_reply_delay_hours, dtype: float64
customer_id
0002-ORFBO 1
0003-MKNFE 3
0004-TLHLJ 1
0011-IGKFF 2
0013-EXCHZ 1
Name: num_complaint_requests, dtype: int64
[52]:
dict_features["total_tickets"] = total_tickets
dict_features["total_interactions"] = total_interactions
dict_features["avg_reply_delay"] = avg_reply_delay
dict_features["num_complaint_requests"] = num_complaint_requests
[53]:
dict_features.keys()
[53]:
dict_keys(['num_request_last_1_months', 'num_request_last_3_months', 'num_request_last_6_months', 'num_request_last_12_months', 'avg_num_days_till_solution', 'avg_num_thread_till_solution', 'last_channel', 'channel_most_used_last6mo', 'total_tickets', 'total_interactions', 'avg_reply_delay', 'num_complaint_requests'])
Zusammenführen aller Features¶
[54]:
# Fasse alle aggregierten Features in einem DataFrame zusammen
df_features = pd.DataFrame(dict_features).reset_index()
print(df_features.shape)
df_features.head()
(6096, 13)
[54]:
| customer_id | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | last_channel | channel_most_used_last6mo | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0002-ORFBO | NaN | NaN | 1.0 | 3.0 | 0.0 | 1.00 | Hotline | Hotline | 1 | 3 | 19.058148 | 1 |
| 1 | 0003-MKNFE | NaN | 3.0 | 4.0 | 4.0 | 0.0 | 1.00 | Social Media | 2 | 4 | 22.865833 | 3 | |
| 2 | 0004-TLHLJ | NaN | 3.0 | 3.0 | 3.0 | 0.0 | 1.00 | Social Media | Chat | 1 | 3 | 7.966481 | 1 |
| 3 | 0011-IGKFF | NaN | NaN | NaN | 1.0 | NaN | NaN | Social Media | NaN | 2 | 3 | 11.924352 | 2 |
| 4 | 0013-EXCHZ | 6.0 | 9.0 | 9.0 | 9.0 | 1.0 | 1.25 | Chat | 5 | 9 | 23.818210 | 1 |
[55]:
df_features.info()
<class 'pandas.DataFrame'>
RangeIndex: 6096 entries, 0 to 6095
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customer_id 6096 non-null str
1 num_request_last_1_months 1365 non-null float64
2 num_request_last_3_months 2338 non-null float64
3 num_request_last_6_months 3191 non-null float64
4 num_request_last_12_months 4198 non-null float64
5 avg_num_days_till_solution 5384 non-null float64
6 avg_num_thread_till_solution 5384 non-null float64
7 last_channel 6096 non-null str
8 channel_most_used_last6mo 3191 non-null str
9 total_tickets 6096 non-null int64
10 total_interactions 6096 non-null int64
11 avg_reply_delay 6096 non-null float64
12 num_complaint_requests 6096 non-null int64
dtypes: float64(7), int64(3), str(3)
memory usage: 741.0 KB
[56]:
df_features.isnull().sum()
[56]:
customer_id 0
num_request_last_1_months 4731
num_request_last_3_months 3758
num_request_last_6_months 2905
num_request_last_12_months 1898
avg_num_days_till_solution 712
avg_num_thread_till_solution 712
last_channel 0
channel_most_used_last6mo 2905
total_tickets 0
total_interactions 0
avg_reply_delay 0
num_complaint_requests 0
dtype: int64
Null-Werte¶
Leere Werte auffüllen - hierbei darauf achten, dass zwischen verschiedenen Datentypen wieder unterschieden werden muss.
In diesem Fall muss man nicht manuell durch alle Spalten durchgehen, sondern kann sich direkt die dtypes zu Nutze machen.
Lösung durch Schleife (ineffizient) vs. pythonic Lösung mit select_dtypes (effizient)¶
Straight-forward way kann eine Schleife die Lösung liefern:
for col in df_features.columns: if df_features[col].dtype == 'object': df_features[col].fillna("", inplace=True) else: df_features[col].fillna(0, inplace=True)Aber effizienter (und „Pythonic“-way) würde man select_dtypes nutzen¶
select_dtypes basiert auf Vektoroperationen, ist somit meist schneller und übersichtlicher als eine explizite Schleife über alle Spalten
[57]:
# Für numerische Spalten
cols_feature_numeric = df_features.select_dtypes(include=[np.number]).columns
df_features[cols_feature_numeric] = df_features[cols_feature_numeric].fillna(0)
# Für string-Spalten
cols_feature_object = df_features.select_dtypes(include=["object"]).columns
df_features[cols_feature_object] = df_features[cols_feature_object].fillna("")
# Ausgabe des Feature-DataFrames
df_features.head()
[57]:
| customer_id | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | last_channel | channel_most_used_last6mo | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0002-ORFBO | 0.0 | 0.0 | 1.0 | 3.0 | 0.0 | 1.00 | Hotline | Hotline | 1 | 3 | 19.058148 | 1 |
| 1 | 0003-MKNFE | 0.0 | 3.0 | 4.0 | 4.0 | 0.0 | 1.00 | Social Media | 2 | 4 | 22.865833 | 3 | |
| 2 | 0004-TLHLJ | 0.0 | 3.0 | 3.0 | 3.0 | 0.0 | 1.00 | Social Media | Chat | 1 | 3 | 7.966481 | 1 |
| 3 | 0011-IGKFF | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.00 | Social Media | 2 | 3 | 11.924352 | 2 | |
| 4 | 0013-EXCHZ | 6.0 | 9.0 | 9.0 | 9.0 | 1.0 | 1.25 | Chat | 5 | 9 | 23.818210 | 1 |
Merge die Features mit der originalen Kunden-Tabelle¶
Beim Merge achten wir darauf, dass der Schlüssel in der Kunden-Tabelle „customerID“ heißt und in features_df „customer_id“
Zudem wollen wir hier einen left-merge, sodass die Originale Kunden-Tabelle auf jeden Fall bestehen bleibt und die Feature-Tabelle „rangemergt“ wird.
[58]:
df_merge = df_onehot_encoded.merge(df_features, left_on="customerID", right_on="customer_id", how="left")
df_merge
[58]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | customer_id | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | last_channel | channel_most_used_last6mo | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7590-VHVEG | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | Hotline | Hotline | 1.0 | 2.0 | 10.169722 | 0.0 |
| 1 | 5575-GNVDE | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5575-GNVDE | 3.0 | 3.0 | 3.0 | 3.0 | 0.5 | 1.0 | Hotline | Hotline | 3.0 | 8.0 | 21.380208 | 1.0 |
| 2 | 3668-QPYBK | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3668-QPYBK | 3.0 | 6.0 | 6.0 | 6.0 | 1.5 | 1.5 | Chat | Hotline | 3.0 | 6.0 | 19.322130 | 1.0 |
| 3 | 7795-CFOCW | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7795-CFOCW | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 | 11.750556 | 1.0 | ||
| 4 | 9237-HQITU | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9237-HQITU | 2.0 | 5.0 | 5.0 | 5.0 | 2.0 | 2.0 | Hotline | 2.0 | 5.0 | 28.044167 | 3.0 | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7027 | 6840-RESVB | 0 | 0 | 1 | 1 | 24 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 84.80 | 1990.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6840-RESVB | 0.0 | 0.0 | 0.0 | 3.0 | 1.0 | 1.0 | 1.0 | 3.0 | 23.803889 | 2.0 | ||
| 7028 | 2234-XADUH | 1 | 0 | 1 | 1 | 72 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 103.20 | 7362.90 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7029 | 4801-JZAZL | 1 | 0 | 1 | 1 | 11 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 29.60 | 346.45 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4801-JZAZL | 0.0 | 0.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 18.954583 | 2.0 | ||
| 7030 | 8361-LTMKD | 0 | 0 | 1 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 74.40 | 306.60 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8361-LTMKD | 0.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | Hotline | Hotline | 1.0 | 2.0 | 10.321667 | 2.0 |
| 7031 | 3186-AJIEK | 0 | 0 | 0 | 0 | 66 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 105.65 | 6844.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
7032 rows × 43 columns
[59]:
# Entferne den doppelten Spaltennamen (customer_id) oder ordne die Spalten neu
df_merge.drop(columns="customer_id", inplace=True)
# Ausgabe der erweiterten Kunden-Tabelle
df_merge.head()
[59]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | last_channel | channel_most_used_last6mo | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | Hotline | Hotline | 1.0 | 2.0 | 10.169722 | 0.0 |
| 1 | 5575-GNVDE | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 3.0 | 3.0 | 3.0 | 0.5 | 1.0 | Hotline | Hotline | 3.0 | 8.0 | 21.380208 | 1.0 |
| 2 | 3668-QPYBK | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 6.0 | 6.0 | 6.0 | 1.5 | 1.5 | Chat | Hotline | 3.0 | 6.0 | 19.322130 | 1.0 |
| 3 | 7795-CFOCW | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 | 11.750556 | 1.0 | ||
| 4 | 9237-HQITU | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 5.0 | 5.0 | 5.0 | 2.0 | 2.0 | Hotline | 2.0 | 5.0 | 28.044167 | 3.0 |
[60]:
df_merge.info()
<class 'pandas.DataFrame'>
RangeIndex: 7032 entries, 0 to 7031
Data columns (total 42 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customerID 7032 non-null str
1 gender 7032 non-null int64
2 SeniorCitizen 7032 non-null int64
3 Partner 7032 non-null int64
4 Dependents 7032 non-null int64
5 tenure 7032 non-null int64
6 PhoneService 7032 non-null int64
7 OnlineSecurity 7032 non-null int64
8 OnlineBackup 7032 non-null int64
9 DeviceProtection 7032 non-null int64
10 TechSupport 7032 non-null int64
11 StreamingTV 7032 non-null int64
12 StreamingMovies 7032 non-null int64
13 PaperlessBilling 7032 non-null int64
14 MonthlyCharges 7032 non-null float64
15 TotalCharges 7032 non-null float64
16 Churn 7032 non-null str
17 MultipleLines_No 7032 non-null int64
18 MultipleLines_No phone service 7032 non-null int64
19 MultipleLines_Yes 7032 non-null int64
20 InternetService_DSL 7032 non-null int64
21 InternetService_Fiber optic 7032 non-null int64
22 InternetService_No 7032 non-null int64
23 Contract_Month-to-month 7032 non-null int64
24 Contract_One year 7032 non-null int64
25 Contract_Two year 7032 non-null int64
26 PaymentMethod_Bank transfer (automatic) 7032 non-null int64
27 PaymentMethod_Credit card (automatic) 7032 non-null int64
28 PaymentMethod_Electronic check 7032 non-null int64
29 PaymentMethod_Mailed check 7032 non-null int64
30 num_request_last_1_months 6087 non-null float64
31 num_request_last_3_months 6087 non-null float64
32 num_request_last_6_months 6087 non-null float64
33 num_request_last_12_months 6087 non-null float64
34 avg_num_days_till_solution 6087 non-null float64
35 avg_num_thread_till_solution 6087 non-null float64
36 last_channel 6087 non-null str
37 channel_most_used_last6mo 6087 non-null str
38 total_tickets 6087 non-null float64
39 total_interactions 6087 non-null float64
40 avg_reply_delay 6087 non-null float64
41 num_complaint_requests 6087 non-null float64
dtypes: float64(12), int64(26), str(4)
memory usage: 2.4 MB
[61]:
df_merge.isnull().sum()
[61]:
customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
PaperlessBilling 0
MonthlyCharges 0
TotalCharges 0
Churn 0
MultipleLines_No 0
MultipleLines_No phone service 0
MultipleLines_Yes 0
InternetService_DSL 0
InternetService_Fiber optic 0
InternetService_No 0
Contract_Month-to-month 0
Contract_One year 0
Contract_Two year 0
PaymentMethod_Bank transfer (automatic) 0
PaymentMethod_Credit card (automatic) 0
PaymentMethod_Electronic check 0
PaymentMethod_Mailed check 0
num_request_last_1_months 945
num_request_last_3_months 945
num_request_last_6_months 945
num_request_last_12_months 945
avg_num_days_till_solution 945
avg_num_thread_till_solution 945
last_channel 945
channel_most_used_last6mo 945
total_tickets 945
total_interactions 945
avg_reply_delay 945
num_complaint_requests 945
dtype: int64
[62]:
df_merge[df_merge["num_request_last_6_months"].isnull()]
[62]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | last_channel | channel_most_used_last6mo | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 9763-GRSKD | 0 | 0 | 1 | 1 | 13 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 49.95 | 587.45 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 30 | 3841-NFECX | 1 | 0 | 1 | 0 | 71 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 96.35 | 6766.95 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 31 | 4929-XIHVW | 0 | 0 | 1 | 0 | 2 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 95.50 | 181.65 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 38 | 5380-WJKOV | 0 | 0 | 0 | 0 | 34 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 106.35 | 3549.25 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 42 | 9867-JCZSP | 1 | 0 | 1 | 1 | 17 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 20.75 | 418.25 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7018 | 2235-DWLJU | 1 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 44.40 | 263.05 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7019 | 0871-OPBXW | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 20.05 | 39.25 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7025 | 7750-EYXWZ | 1 | 0 | 0 | 0 | 12 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 60.65 | 743.30 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7028 | 2234-XADUH | 1 | 0 | 1 | 1 | 72 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 103.20 | 7362.90 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7031 | 3186-AJIEK | 0 | 0 | 0 | 0 | 66 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 105.65 | 6844.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
945 rows × 42 columns
[63]:
df_service[df_service["customer_id"]=="9763-GRSKD"]
[63]:
| ticket_id | customer_id | time_request | time_reply | channel | request | reply | solved | original_request | original_ticket_id | reply_delay_hours | is_complaint |
|---|
Den finalen DataFrame auffüllen¶
[64]:
# Für numerische Spalten
numeric_cols = df_merge.select_dtypes(include=[np.number]).columns
df_merge[numeric_cols] = df_merge[numeric_cols].fillna(0)
# Für string-Spalten
object_cols = df_merge.select_dtypes(include=["object"]).columns
df_merge[object_cols] = df_merge[object_cols].fillna("")
[65]:
df_merge.isnull().sum()
[65]:
customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
PaperlessBilling 0
MonthlyCharges 0
TotalCharges 0
Churn 0
MultipleLines_No 0
MultipleLines_No phone service 0
MultipleLines_Yes 0
InternetService_DSL 0
InternetService_Fiber optic 0
InternetService_No 0
Contract_Month-to-month 0
Contract_One year 0
Contract_Two year 0
PaymentMethod_Bank transfer (automatic) 0
PaymentMethod_Credit card (automatic) 0
PaymentMethod_Electronic check 0
PaymentMethod_Mailed check 0
num_request_last_1_months 0
num_request_last_3_months 0
num_request_last_6_months 0
num_request_last_12_months 0
avg_num_days_till_solution 0
avg_num_thread_till_solution 0
last_channel 0
channel_most_used_last6mo 0
total_tickets 0
total_interactions 0
avg_reply_delay 0
num_complaint_requests 0
dtype: int64
[66]:
df_merge.head()
[66]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | last_channel | channel_most_used_last6mo | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | Hotline | Hotline | 1.0 | 2.0 | 10.169722 | 0.0 |
| 1 | 5575-GNVDE | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 3.0 | 3.0 | 3.0 | 0.5 | 1.0 | Hotline | Hotline | 3.0 | 8.0 | 21.380208 | 1.0 |
| 2 | 3668-QPYBK | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 6.0 | 6.0 | 6.0 | 1.5 | 1.5 | Chat | Hotline | 3.0 | 6.0 | 19.322130 | 1.0 |
| 3 | 7795-CFOCW | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 | 11.750556 | 1.0 | ||
| 4 | 9237-HQITU | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 5.0 | 5.0 | 5.0 | 2.0 | 2.0 | Hotline | 2.0 | 5.0 | 28.044167 | 3.0 |
[67]:
df_merge.dtypes
[67]:
customerID str
gender int64
SeniorCitizen int64
Partner int64
Dependents int64
tenure int64
PhoneService int64
OnlineSecurity int64
OnlineBackup int64
DeviceProtection int64
TechSupport int64
StreamingTV int64
StreamingMovies int64
PaperlessBilling int64
MonthlyCharges float64
TotalCharges float64
Churn str
MultipleLines_No int64
MultipleLines_No phone service int64
MultipleLines_Yes int64
InternetService_DSL int64
InternetService_Fiber optic int64
InternetService_No int64
Contract_Month-to-month int64
Contract_One year int64
Contract_Two year int64
PaymentMethod_Bank transfer (automatic) int64
PaymentMethod_Credit card (automatic) int64
PaymentMethod_Electronic check int64
PaymentMethod_Mailed check int64
num_request_last_1_months float64
num_request_last_3_months float64
num_request_last_6_months float64
num_request_last_12_months float64
avg_num_days_till_solution float64
avg_num_thread_till_solution float64
last_channel str
channel_most_used_last6mo str
total_tickets float64
total_interactions float64
avg_reply_delay float64
num_complaint_requests float64
dtype: object
Transform categorical columns¶
[68]:
cols_merge_object = ["last_channel", "channel_most_used_last6mo"]
df_final = pd.get_dummies(df_merge, columns=cols_merge_object, dtype=int)
print(df_final.shape)
df_final
(7032, 52)
[68]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | last_channel_ | last_channel_Chat | last_channel_Email | last_channel_Hotline | last_channel_On-site | last_channel_Social Media | channel_most_used_last6mo_ | channel_most_used_last6mo_Chat | channel_most_used_last6mo_Email | channel_most_used_last6mo_Hotline | channel_most_used_last6mo_On-site | channel_most_used_last6mo_Social Media | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 10.169722 | 0.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 5575-GNVDE | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 3.0 | 3.0 | 3.0 | 0.5 | 1.0 | 3.0 | 8.0 | 21.380208 | 1.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 3668-QPYBK | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 6.0 | 6.0 | 6.0 | 1.5 | 1.5 | 3.0 | 6.0 | 19.322130 | 1.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 7795-CFOCW | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 | 11.750556 | 1.0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 9237-HQITU | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 5.0 | 5.0 | 5.0 | 2.0 | 2.0 | 2.0 | 5.0 | 28.044167 | 3.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7027 | 6840-RESVB | 0 | 0 | 1 | 1 | 24 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 84.80 | 1990.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 3.0 | 1.0 | 1.0 | 1.0 | 3.0 | 23.803889 | 2.0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7028 | 2234-XADUH | 1 | 0 | 1 | 1 | 72 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 103.20 | 7362.90 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7029 | 4801-JZAZL | 1 | 0 | 1 | 1 | 11 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 29.60 | 346.45 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 18.954583 | 2.0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 7030 | 8361-LTMKD | 0 | 0 | 1 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 74.40 | 306.60 | Yes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 10.321667 | 2.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 7031 | 3186-AJIEK | 0 | 0 | 0 | 0 | 66 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 105.65 | 6844.50 | No | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
7032 rows × 52 columns
Don’t forget the Target Variable!¶
[69]:
df_final['Churn'] = df_final['Churn'].map({"Yes": 1, "No": 0})
df_final.head()
[69]:
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | last_channel_ | last_channel_Chat | last_channel_Email | last_channel_Hotline | last_channel_On-site | last_channel_Social Media | channel_most_used_last6mo_ | channel_most_used_last6mo_Chat | channel_most_used_last6mo_Email | channel_most_used_last6mo_Hotline | channel_most_used_last6mo_On-site | channel_most_used_last6mo_Social Media | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 10.169722 | 0.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 5575-GNVDE | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 3.0 | 3.0 | 3.0 | 0.5 | 1.0 | 3.0 | 8.0 | 21.380208 | 1.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 3668-QPYBK | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 6.0 | 6.0 | 6.0 | 1.5 | 1.5 | 3.0 | 6.0 | 19.322130 | 1.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 7795-CFOCW | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 | 11.750556 | 1.0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 9237-HQITU | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 5.0 | 5.0 | 5.0 | 2.0 | 2.0 | 2.0 | 5.0 | 28.044167 | 3.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
[70]:
## Verwerfe ID-columns
if "customerID" in df_final:
df_final.drop("customerID", axis=1, inplace=True)
df_final
[70]:
| gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | last_channel_ | last_channel_Chat | last_channel_Email | last_channel_Hotline | last_channel_On-site | last_channel_Social Media | channel_most_used_last6mo_ | channel_most_used_last6mo_Chat | channel_most_used_last6mo_Email | channel_most_used_last6mo_Hotline | channel_most_used_last6mo_On-site | channel_most_used_last6mo_Social Media | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 10.169722 | 0.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 3.0 | 3.0 | 3.0 | 0.5 | 1.0 | 3.0 | 8.0 | 21.380208 | 1.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 6.0 | 6.0 | 6.0 | 1.5 | 1.5 | 3.0 | 6.0 | 19.322130 | 1.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 | 11.750556 | 1.0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 5.0 | 5.0 | 5.0 | 2.0 | 2.0 | 2.0 | 5.0 | 28.044167 | 3.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7027 | 0 | 0 | 1 | 1 | 24 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 84.80 | 1990.50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 3.0 | 1.0 | 1.0 | 1.0 | 3.0 | 23.803889 | 2.0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7028 | 1 | 0 | 1 | 1 | 72 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 103.20 | 7362.90 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7029 | 1 | 0 | 1 | 1 | 11 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 29.60 | 346.45 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 18.954583 | 2.0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 7030 | 0 | 0 | 1 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 74.40 | 306.60 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 10.321667 | 2.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 7031 | 0 | 0 | 0 | 0 | 66 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 105.65 | 6844.50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
7032 rows × 51 columns
Kunden-IDs:¶
Jetzt, wo die Tabellen gemergt sind, können wir als letzten Schritt vor dem Split des Datensatzes die einzig uebrig gebliebene Kunden-ID Spalte entfernen
[71]:
if "customerID" in df_final:
df_final.drop("customerID", axis=1, inplace=True)
df_final
[71]:
| gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | OnlineSecurity | OnlineBackup | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | PaperlessBilling | MonthlyCharges | TotalCharges | Churn | MultipleLines_No | MultipleLines_No phone service | MultipleLines_Yes | InternetService_DSL | InternetService_Fiber optic | InternetService_No | Contract_Month-to-month | Contract_One year | Contract_Two year | PaymentMethod_Bank transfer (automatic) | PaymentMethod_Credit card (automatic) | PaymentMethod_Electronic check | PaymentMethod_Mailed check | num_request_last_1_months | num_request_last_3_months | num_request_last_6_months | num_request_last_12_months | avg_num_days_till_solution | avg_num_thread_till_solution | total_tickets | total_interactions | avg_reply_delay | num_complaint_requests | last_channel_ | last_channel_Chat | last_channel_Email | last_channel_Hotline | last_channel_On-site | last_channel_Social Media | channel_most_used_last6mo_ | channel_most_used_last6mo_Chat | channel_most_used_last6mo_Email | channel_most_used_last6mo_Hotline | channel_most_used_last6mo_On-site | channel_most_used_last6mo_Social Media | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 29.85 | 29.85 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 10.169722 | 0.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 34 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 56.95 | 1889.50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 3.0 | 3.0 | 3.0 | 0.5 | 1.0 | 3.0 | 8.0 | 21.380208 | 1.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 53.85 | 108.15 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.0 | 6.0 | 6.0 | 6.0 | 1.5 | 1.5 | 3.0 | 6.0 | 19.322130 | 1.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 45 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 42.30 | 1840.75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 2.0 | 11.750556 | 1.0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 70.70 | 151.65 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.0 | 5.0 | 5.0 | 5.0 | 2.0 | 2.0 | 2.0 | 5.0 | 28.044167 | 3.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7027 | 0 | 0 | 1 | 1 | 24 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 84.80 | 1990.50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 3.0 | 1.0 | 1.0 | 1.0 | 3.0 | 23.803889 | 2.0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7028 | 1 | 0 | 1 | 1 | 72 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 103.20 | 7362.90 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7029 | 1 | 0 | 1 | 1 | 11 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 29.60 | 346.45 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 18.954583 | 2.0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 7030 | 0 | 0 | 1 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 74.40 | 306.60 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 2.0 | 2.0 | 2.0 | 0.0 | 1.0 | 1.0 | 2.0 | 10.321667 | 2.0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 7031 | 0 | 0 | 0 | 0 | 66 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 105.65 | 6844.50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
7032 rows × 51 columns
Split the Data to x_train, x_test, y_train, y_test¶
[72]:
# Split X and y
X = df_final.drop(columns = ['Churn'])
y = df_final['Churn'].values
[73]:
# Splitting the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30, random_state = 42, stratify=y)
Normalization¶
How to scale/normalize the numerical columns?
[74]:
cols_ori_numeric
[74]:
['tenure', 'MonthlyCharges', 'TotalCharges']
[75]:
cols_feature_numeric
[75]:
Index(['num_request_last_1_months', 'num_request_last_3_months',
'num_request_last_6_months', 'num_request_last_12_months',
'avg_num_days_till_solution', 'avg_num_thread_till_solution',
'total_tickets', 'total_interactions', 'avg_reply_delay',
'num_complaint_requests'],
dtype='str')
[76]:
numeric_final_cols = cols_ori_numeric + cols_feature_numeric.tolist()
numeric_final_cols
[76]:
['tenure',
'MonthlyCharges',
'TotalCharges',
'num_request_last_1_months',
'num_request_last_3_months',
'num_request_last_6_months',
'num_request_last_12_months',
'avg_num_days_till_solution',
'avg_num_thread_till_solution',
'total_tickets',
'total_interactions',
'avg_reply_delay',
'num_complaint_requests']
[77]:
def distplot(feature, frame, color="r"):
plt.figure(figsize=(8,3))
plt.title("Verteilung für {}".format(feature))
ax = sns.distplot(frame[feature], color= color)
[78]:
for feat in numeric_final_cols:
distplot(feat, df_final)
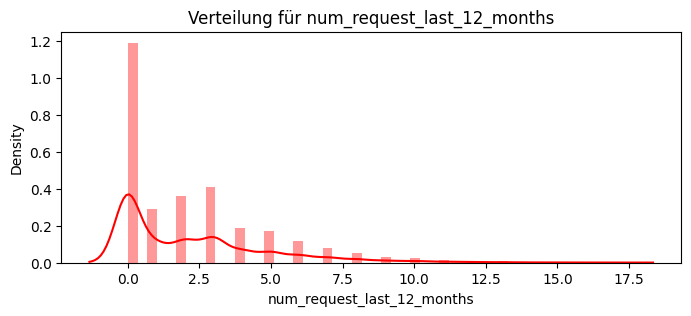
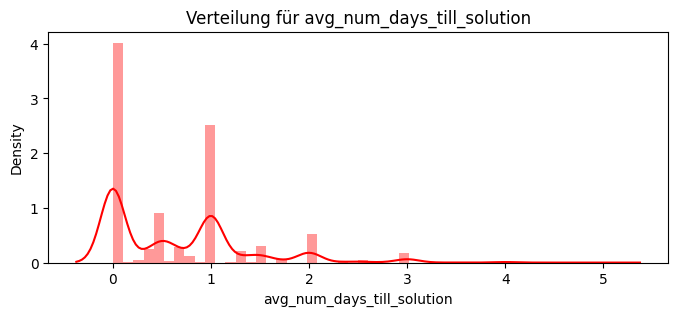
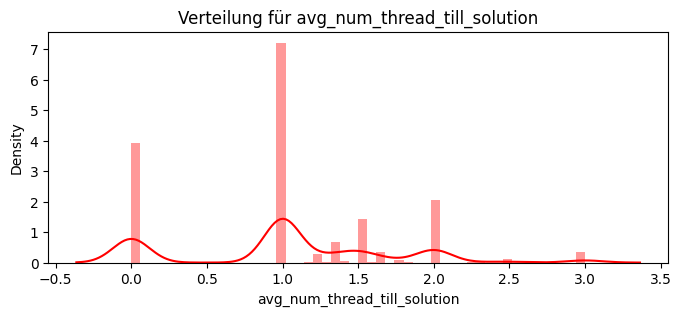
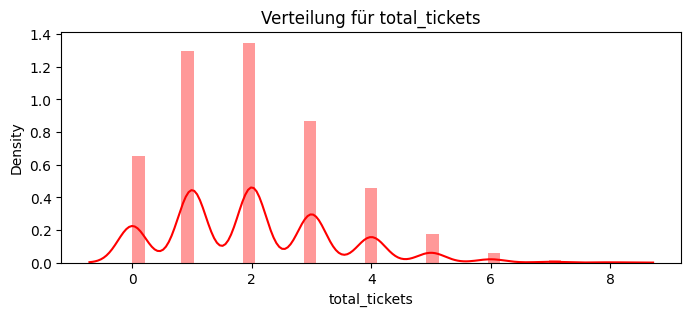
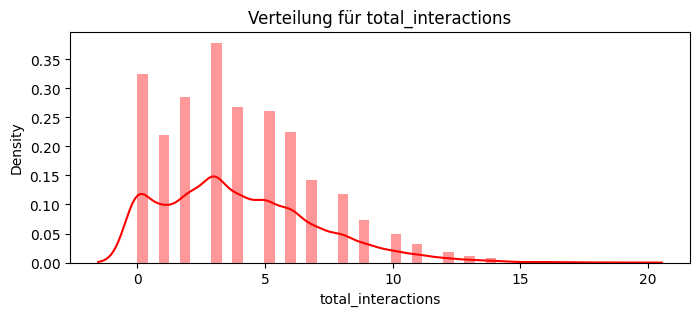
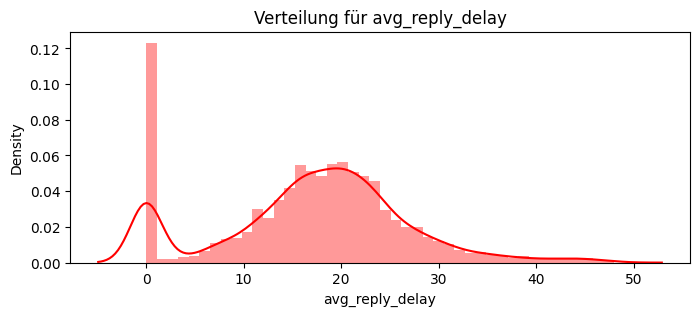
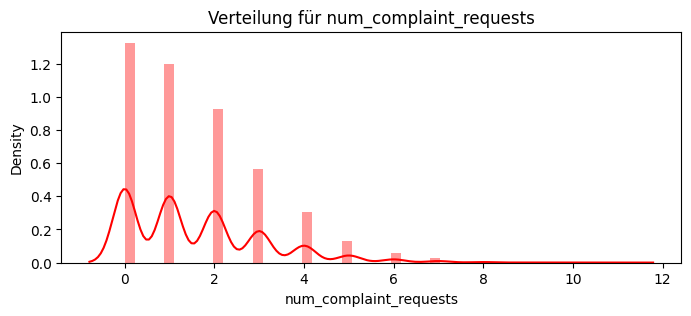
Überlegung: Welchen Scaler sollte ich nutzen?¶
Da die numerischen Features über verschiedene Wertebereiche (value ranges) verteilt sind, nutzen wir hier den Standard Scalar, um sie alle auf den gleichen Bereich runterzuskalieren.
Normalisiere die numerischen Attribute¶
[79]:
df_std = pd.DataFrame(StandardScaler().fit_transform(df_final[numeric_final_cols].astype("float64")),
columns=numeric_final_cols)
for feat in numeric_final_cols:
distplot(feat, df_std, color="c")
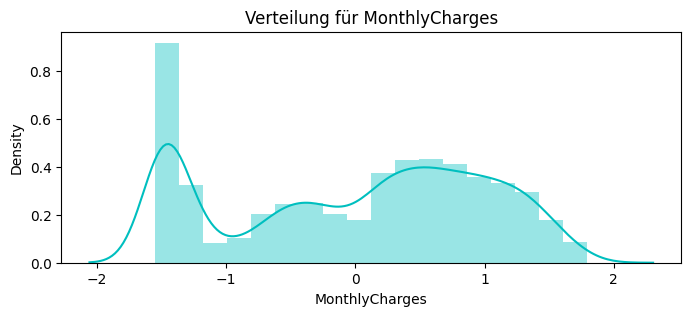
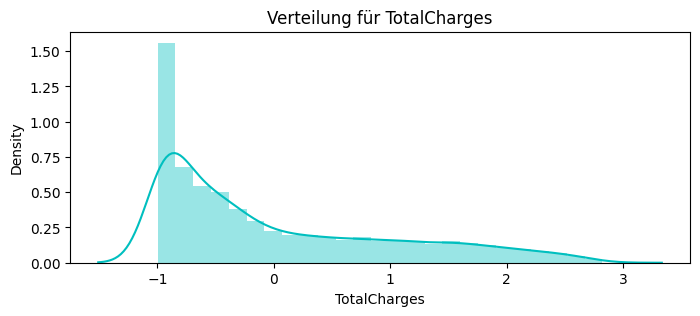
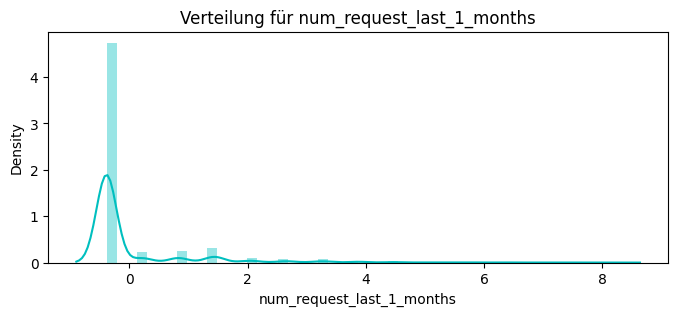
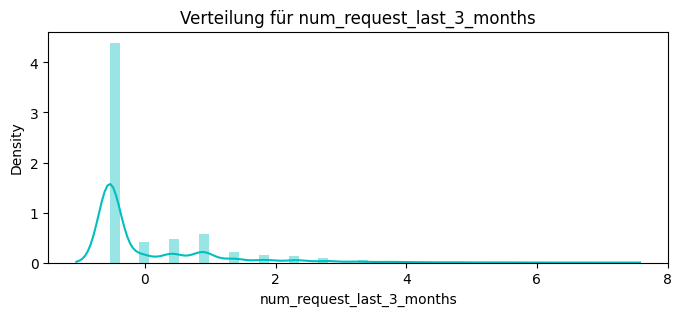
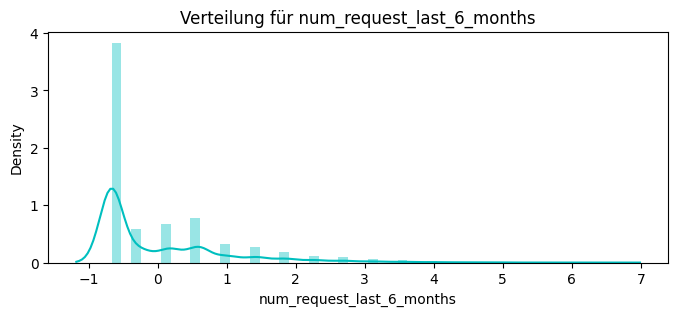
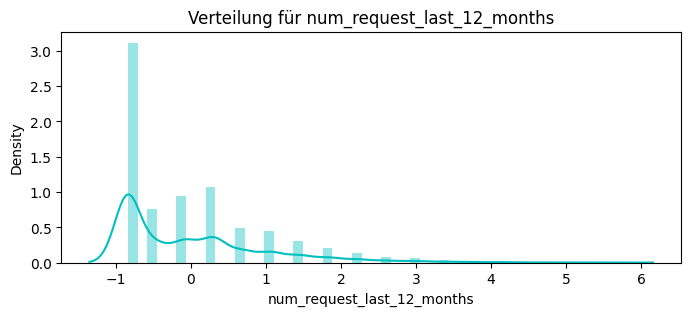
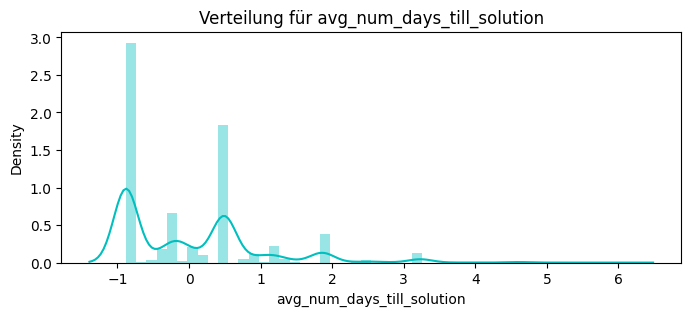
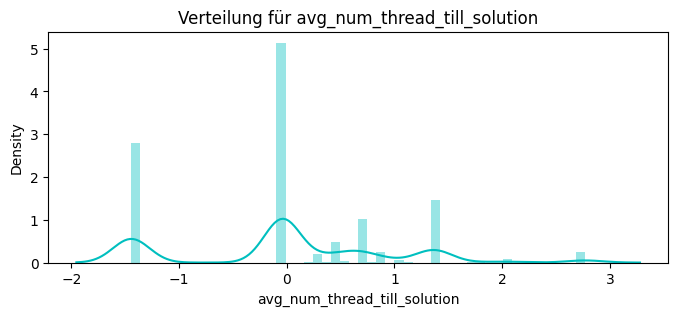
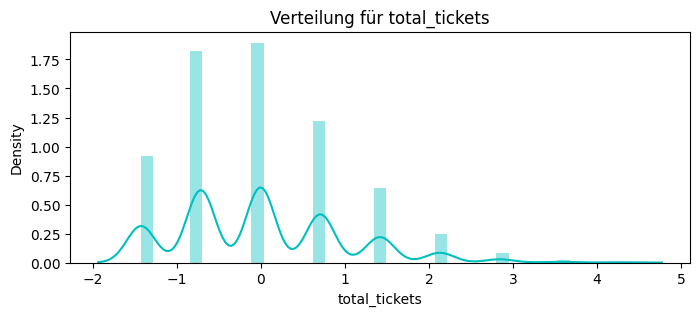
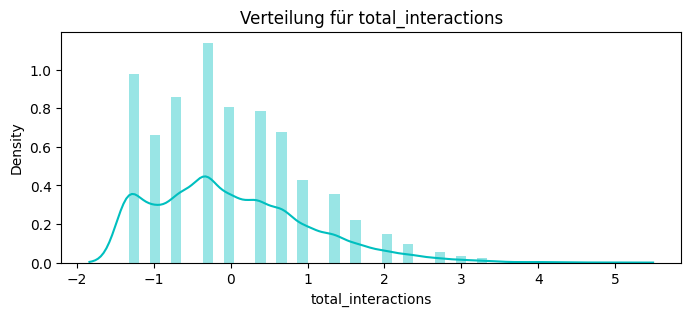
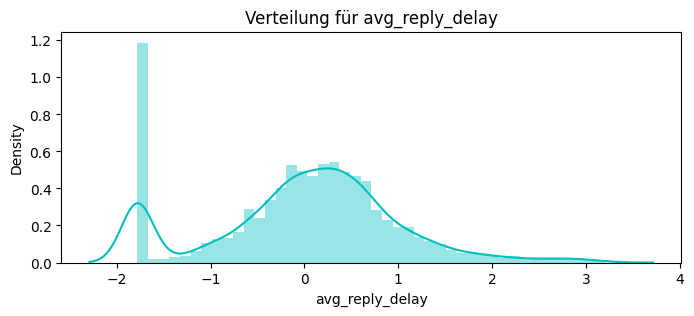
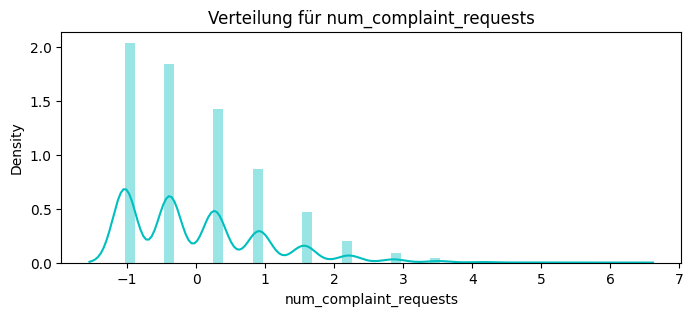
[80]:
scaler= StandardScaler()
X_train[numeric_final_cols] = scaler.fit_transform(X_train[numeric_final_cols])
X_test[numeric_final_cols] = scaler.transform(X_test[numeric_final_cols])
Modellieren¶
Es handelt sich hierbei um einen Datensatz mit klar definierten Labels (Churn: Yes oder No), die eine Klassifikationsproblematik beschreiben.
Dazu werden wir nun mehrere Klassifikationsmodelle testen.
K-Nearest Neighbor Classifier¶
Der K-Nearest-Neighbor Classifier ist eine nichtparametrische Methode zur Schätzung von Wahrscheinlichkeitsdichtefunktionen, mehr Details: https://de.wikipedia.org/wiki/N%C3%A4chste-Nachbarn-Klassifikation
Hier nutzen wir die kNN-Implemtation von scikit-learn: https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
[81]:
# Initiere das knn-Modell
knn_model = KNeighborsClassifier(n_neighbors = 11)
[82]:
# Trainiere das Modell mit unseren Trainingsdaten
knn_model.fit(X_train,y_train)
[82]:
KNeighborsClassifier(n_neighbors=11)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
[83]:
# die "score"-Funktion scoret direkt die predicted Resultate vom X_test gegen die wahren y-Werte und gibt die Accuracy zurück
accuracy_knn = knn_model.score(X_test, y_test)
print("KNN accuracy:",accuracy_knn)
print(knn_model.score(X_test,y_test))
KNN accuracy: 0.7663507109004739
0.7663507109004739
[84]:
# Alternativ kann man direkt mit dem Modell auf den X_test (Testdatensatz) vorhersagen und diese Vorhersagen gegen die wahren Werte des Testdatensatzes mit sklearn evaluieren
y_pred = knn_model.predict(X_test)
prec = precision_score(y_test, y_pred, average=None)
recall = recall_score(y_test, y_pred, average=None)
print(f"Precision for class 0: {prec[0]}, precision for class 1: {prec[1]}")
print(f"Recall for class 0: {recall[0]}, recall for class 1: {recall[1]}")
Precision for class 0: 0.8102232667450059, precision for class 1: 0.5833333333333334
Recall for class 0: 0.8902517753389283, recall for class 1: 0.42424242424242425
[85]:
prec = precision_score(y_test, y_pred, pos_label=1)
print(prec)
recall = recall_score(y_test, y_pred, pos_label=1)
print(recall)
0.5833333333333334
0.42424242424242425
[86]:
# Zudem gibt es den "Classification Report", der direkt mehrere Metriken Resultate ausgibt
print(classification_report(y_test, y_pred))
precision recall f1-score support
0 0.81 0.89 0.85 1549
1 0.58 0.42 0.49 561
accuracy 0.77 2110
macro avg 0.70 0.66 0.67 2110
weighted avg 0.75 0.77 0.75 2110
Logistic Regression Classifier¶
Der Logistic Regression Classifier basiert auf Linear Regression, nur gibt sie am Ende eine
[87]:
lr_model = LogisticRegression()
lr_model.fit(X_train,y_train)
accuracy_lr = lr_model.score(X_test,y_test)
print("Logistic Regression accuracy is :",accuracy_lr)
Logistic Regression accuracy is : 0.7943127962085308
[88]:
# Make predictions
lr_pred= lr_model.predict(X_test)
report = classification_report(y_test,lr_pred)
print(report)
precision recall f1-score support
0 0.83 0.90 0.86 1549
1 0.64 0.51 0.57 561
accuracy 0.79 2110
macro avg 0.74 0.70 0.72 2110
weighted avg 0.78 0.79 0.79 2110
[89]:
plt.figure(figsize=(4,3))
sns.heatmap(confusion_matrix(y_test, lr_pred),
annot=True,fmt = "d",linecolor="k",linewidths=3)
plt.title("LOGISTIC REGRESSION CONFUSION MATRIX",fontsize=14)
plt.show()
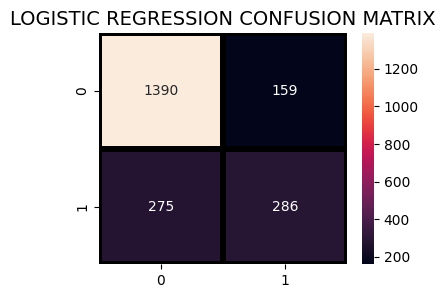
Decision Tree Classifier¶
[90]:
dt_model = DecisionTreeClassifier()
dt_model.fit(X_train,y_train)
y_pred = dt_model.predict(X_test)
accuracy_dt = dt_model.score(X_test, y_test)
print("Decision Tree accuracy is :",accuracy_dt)
Decision Tree accuracy is : 0.7161137440758294
[91]:
print(classification_report(y_test, y_pred))
precision recall f1-score support
0 0.81 0.80 0.80 1549
1 0.47 0.50 0.48 561
accuracy 0.72 2110
macro avg 0.64 0.65 0.64 2110
weighted avg 0.72 0.72 0.72 2110
AdaBoost Classifier¶
[92]:
a_model = AdaBoostClassifier()
a_model.fit(X_train,y_train)
a_preds = a_model.predict(X_test)
print("AdaBoost Classifier accuracy")
metrics.accuracy_score(y_test, a_preds)
AdaBoost Classifier accuracy
[92]:
0.7924170616113744
[93]:
print(classification_report(y_test, a_preds))
precision recall f1-score support
0 0.83 0.90 0.86 1549
1 0.64 0.49 0.56 561
accuracy 0.79 2110
macro avg 0.74 0.70 0.71 2110
weighted avg 0.78 0.79 0.78 2110
[94]:
plt.figure(figsize=(4,3))
sns.heatmap(confusion_matrix(y_test, a_preds),
annot=True,fmt = "d",linecolor="k",linewidths=3)
plt.title("AdaBoost Classifier Confusion Matrix",fontsize=14)
plt.show()
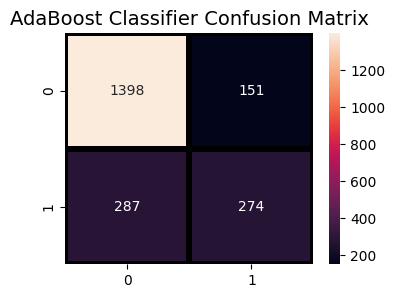
Gradient Boosting Classifier¶
[95]:
gb = GradientBoostingClassifier()
gb.fit(X_train, y_train)
gb_pred = gb.predict(X_test)
print("Gradient Boosting Classifier", accuracy_score(y_test, gb_pred))
Gradient Boosting Classifier 0.790521327014218
[96]:
print(classification_report(y_test, gb_pred))
precision recall f1-score support
0 0.83 0.90 0.86 1549
1 0.64 0.49 0.56 561
accuracy 0.79 2110
macro avg 0.73 0.70 0.71 2110
weighted avg 0.78 0.79 0.78 2110
[97]:
plt.figure(figsize=(4,3))
sns.heatmap(confusion_matrix(y_test, gb_pred),
annot=True,fmt = "d",linecolor="k",linewidths=3)
plt.title("Gradient Boosting Classifier Confusion Matrix",fontsize=14)
plt.show()
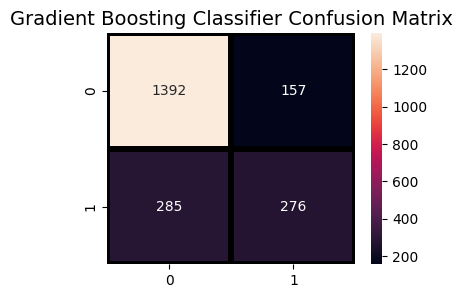
Voting Classifier¶
Der Voting Classifier ist ein Mixture Modell, der mehrere Modelle vereint, die alle ihre Predictions machen und dann über Majority voting entschieden wird, welche Prediction Output rausgegeben wird.
[98]:
from sklearn.ensemble import VotingClassifier
clf1 = GradientBoostingClassifier()
clf2 = LogisticRegression()
clf3 = AdaBoostClassifier()
eclf1 = VotingClassifier(estimators=[("gbc", clf1), ("lr", clf2), ("abc", clf3)], voting="soft")
eclf1.fit(X_train, y_train)
predictions = eclf1.predict(X_test)
print("Final Accuracy Score ")
print(accuracy_score(y_test, predictions))
Final Accuracy Score
0.7933649289099526
[99]:
print(classification_report(y_test, predictions))
precision recall f1-score support
0 0.83 0.90 0.86 1549
1 0.64 0.50 0.56 561
accuracy 0.79 2110
macro avg 0.74 0.70 0.71 2110
weighted avg 0.78 0.79 0.78 2110
[100]:
plt.figure(figsize=(4,3))
sns.heatmap(confusion_matrix(y_test, predictions),
annot=True,fmt = "d",linecolor="k",linewidths=3)
plt.title("FINAL CONFUSION MATRIX",fontsize=14)
plt.show()
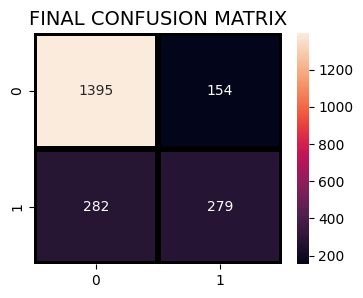
Cross Validation Example!¶
Anhand eines einfachen Decision Trees¶
[101]:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import KFold, cross_validate
import numpy as np
[102]:
# Annahme: X und y beinhalten jeweils deine Feature-Matrix und Zielvariable (Churn als 0/1)
dt_model = DecisionTreeClassifier()
dt_model
[102]:
DecisionTreeClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Wähle k=10 für 10-fold Cross-Validation¶
[103]:
k = 10
kf = KFold(n_splits=k, shuffle=True, random_state=42)
kf
[103]:
KFold(n_splits=10, random_state=42, shuffle=True)
Verwende cross_validate, um sowohl Trainings- als auch Validierungsscores zu erhalten¶
[104]:
cv_results = cross_validate(dt_model, X, y, cv=kf, return_train_score=True)
cv_results
[104]:
{'fit_time': array([0.03874516, 0.04276395, 0.03619814, 0.03640604, 0.0356729 ,
0.03642106, 0.03842902, 0.03649712, 0.036309 , 0.03726411]),
'score_time': array([0.00107479, 0.00114584, 0.00121593, 0.00115991, 0.00108218,
0.00104594, 0.00105691, 0.00105095, 0.0015471 , 0.00119972]),
'test_score': array([0.73579545, 0.68892045, 0.7254623 , 0.74253201, 0.70981508,
0.70981508, 0.7254623 , 0.68421053, 0.69274538, 0.7254623 ]),
'train_score': array([0.99968394, 0.99984197, 0.999842 , 0.99968399, 0.999842 ,
0.99968399, 0.99968399, 0.99968399, 0.99968399, 0.99968399])}
Logge die Ergebnisse jeder einzelnen Fold¶
[105]:
print("Trainings-Scores pro Fold:")
print(cv_results["train_score"])
Trainings-Scores pro Fold:
[0.99968394 0.99984197 0.999842 0.99968399 0.999842 0.99968399
0.99968399 0.99968399 0.99968399 0.99968399]
[106]:
print("Validierungs-Scores pro Fold:")
print(cv_results["test_score"])
Validierungs-Scores pro Fold:
[0.73579545 0.68892045 0.7254623 0.74253201 0.70981508 0.70981508
0.7254623 0.68421053 0.69274538 0.7254623 ]
[107]:
print("Durchschnittlicher Validierungs-Score:")
print(np.mean(cv_results["test_score"]))
Durchschnittlicher Validierungs-Score:
0.7140220887753783
Next Step¶
Falls es sich hierbei um ein sehr einfaches Modell handelt ohne jegliche Parameter (z.B. linear Regression oder logistic Regression), könnte man nun das Modell mit dem besten Validierungs-Score extrahieren.
Cross-Validation¶
teilt die Daten auf und trainiert/evaluiert das Modell mehrfach (k-fach).
Komplexere Modelle?¶
Wenn es sich um ein komplexeres Modell mit Hyperparameter handelt, kann sie helfen für das jeweilge Set an Hyperparameter eine robuste Performance-Metrik zu erhalten – sie ändert aber nicht selbst die Hyperparameter.
Hyperparameter-Tuning (z. B. mit GridSearchCV)¶
Hyperparameter-Tuning (z. B. mit GridSearchCV) verwendet CV (Cross-Validation), um verschiedene Hyperparameter-Kombinationen zu vergleichen, und wählt so die optimale Konfiguration.
[108]:
# Beispiel anhand Decision Tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
[109]:
# Definiere den Parameterbereich
param_grid = {
"max_depth": [None, 3, 5, 10, 20], # default=None
"min_samples_split": [2, 5, 10] # default=2, notwendige Anzahl an data points in einem Knoten, fürs weitere Teilen dieses Knoten
}
param_grid
[109]:
{'max_depth': [None, 3, 5, 10, 20], 'min_samples_split': [2, 5, 10]}
[110]:
# GridSearchCV kombiniert CV mit dem Hyperparameter-Tuning
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=10, return_train_score=True)
grid_search.fit(X, y)
[110]:
GridSearchCV(cv=10, estimator=DecisionTreeClassifier(),
param_grid={'max_depth': [None, 3, 5, 10, 20],
'min_samples_split': [2, 5, 10]},
return_train_score=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
DecisionTreeClassifier(max_depth=5, min_samples_split=10)
Parameters
[111]:
# Beste Parameter und entsprechender Score
print("Beste Parameter:", grid_search.best_params_)
print("Bester CV-Score:", grid_search.best_score_)
Beste Parameter: {'max_depth': 5, 'min_samples_split': 10}
Bester CV-Score: 0.7912374321091427
[112]:
# Das finale Modell (trainiert auf den gesamten Daten mit den besten Parametern)
best_model = grid_search.best_estimator_
[113]:
y_pred_best = best_model.predict(X_test)
acc_best = accuracy_score(y_test, y_pred_best)
print(acc_best)
prec_best = precision_score(y_test, y_pred_best, pos_label=1)
print(prec_best)
recall_best = recall_score(y_test, y_pred_best, pos_label=1)
print(recall_best)
0.7341232227488151
0.0
0.0
[114]:
1 in y_test
[114]:
True
[115]:
1 in y_pred
[115]:
True
[116]:
y_test
[116]:
array([0, 0, 0, ..., 0, 0, 0], shape=(2110,))
[117]:
y_pred
[117]:
array([0, 0, 0, ..., 0, 0, 0], shape=(2110,))
Accuracy wurde genutzt - was wenn wir precision nutzen wollen?¶
[118]:
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
param_grid = {"max_depth": [None, 3, 5, 10, 20],
"min_samples_split": [2, 5, 10]}
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid,
cv=10, scoring="precision", refit=True)
grid_search.fit(X, y)
print("Beste Parameter:", grid_search.best_params_)
print("Bester CV-Precision-Score:", grid_search.best_score_)
best_model = grid_search.best_estimator_
Beste Parameter: {'max_depth': 5, 'min_samples_split': 10}
Bester CV-Precision-Score: 0.6664281647925435
[119]:
y_pred_best = best_model.predict(X_test)
acc_best = accuracy_score(y_test, y_pred_best)
print(acc_best)
prec_best = precision_score(y_test, y_pred_best, pos_label=1)
print(prec_best)
recall_best = recall_score(y_test, y_pred_best, pos_label=1)
print(recall_best)
0.7341232227488151
0.0
0.0
Können wir mehrere Metriken gleichzeitig überwachen?¶
[120]:
from sklearn.metrics import make_scorer, precision_score, recall_score
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
param_grid = {"max_depth": [None, 3, 5, 10, 20],
"min_samples_split": [2, 5, 10]}
scoring = {
"precision": make_scorer(precision_score, pos_label=1),
"recall": make_scorer(recall_score, pos_label=1)
}
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid,
cv=10, scoring=scoring, refit="precision") # refit='precision' lässt das finale Modell auf den besten Precision-Score ausgewählen.
grid_search.fit(X, y)
# Es werden alle Scores zurückgegeben:
cv_results = grid_search.cv_results_
print("Beste Parameter:", grid_search.best_params_)
print("Bester CV-Precision-Score:", grid_search.best_score_)
# Die Ergebnisse aller Folds (z.B. Precision und Recall) kannst du so ausgeben:
for mean_score, params in zip(cv_results["mean_test_precision"], cv_results["params"]):
print(f"Params: {params} - Mean Precision: {mean_score:.4f}")
best_model = grid_search.best_estimator_
Beste Parameter: {'max_depth': 5, 'min_samples_split': 10}
Bester CV-Precision-Score: 0.6670314466458254
Params: {'max_depth': None, 'min_samples_split': 2} - Mean Precision: 0.4795
Params: {'max_depth': None, 'min_samples_split': 5} - Mean Precision: 0.4939
Params: {'max_depth': None, 'min_samples_split': 10} - Mean Precision: 0.5079
Params: {'max_depth': 3, 'min_samples_split': 2} - Mean Precision: 0.6475
Params: {'max_depth': 3, 'min_samples_split': 5} - Mean Precision: 0.6475
Params: {'max_depth': 3, 'min_samples_split': 10} - Mean Precision: 0.6475
Params: {'max_depth': 5, 'min_samples_split': 2} - Mean Precision: 0.6660
Params: {'max_depth': 5, 'min_samples_split': 5} - Mean Precision: 0.6656
Params: {'max_depth': 5, 'min_samples_split': 10} - Mean Precision: 0.6670
Params: {'max_depth': 10, 'min_samples_split': 2} - Mean Precision: 0.5477
Params: {'max_depth': 10, 'min_samples_split': 5} - Mean Precision: 0.5497
Params: {'max_depth': 10, 'min_samples_split': 10} - Mean Precision: 0.5505
Params: {'max_depth': 20, 'min_samples_split': 2} - Mean Precision: 0.4877
Params: {'max_depth': 20, 'min_samples_split': 5} - Mean Precision: 0.4937
Params: {'max_depth': 20, 'min_samples_split': 10} - Mean Precision: 0.5072
[121]:
y_pred_best = best_model.predict(X_test)
acc_best = accuracy_score(y_test, y_pred_best)
print(acc_best)
prec_best = precision_score(y_test, y_pred_best, pos_label=1)
print(prec_best)
recall_best = recall_score(y_test, y_pred_best, pos_label=1)
print(recall_best)
0.7341232227488151
0.0
0.0
Vorhergesagte Wahrscheinlichkeit (anstatt der zugeteilten Klasse)¶
Viele Klassifikationsmodelle in scikit-learn bieten die Methode predict_proba(), mit der wir die Wahrscheinlichkeit für jeden Datenpunkt und jede Klasse abrufen können.
Bei einem binären Klassifikationsmodell liefert predict_proba() ein Array der Form (n_samples, 2), wobei die zweite Spalte (Index 1) die Wahrscheinlichkeit für Klasse 1 enthält.
[122]:
# Hole die Wahrscheinlichkeiten für den Testdatensatz
y_prob = best_model.predict_proba(X_test)
y_prob
[122]:
array([[0.65269461, 0.34730539],
[0.65269461, 0.34730539],
[0.65269461, 0.34730539],
...,
[0.65269461, 0.34730539],
[0.65269461, 0.34730539],
[0.65269461, 0.34730539]], shape=(2110, 2))
[123]:
# Extrahiere die Wahrscheinlichkeit für Klasse 1
y_prob_class1 = y_prob[:, 1]
y_prob_class1
[123]:
array([0.34730539, 0.34730539, 0.34730539, ..., 0.34730539, 0.34730539,
0.34730539], shape=(2110,))
[124]:
# Definiere einen eigenen Schwellenwert (Threshold)
threshold = 0.3 # Beispiel: 30% statt des üblichen 0.5
# Wende den Threshold an: Werte >= threshold werden als 1 klassifiziert, ansonsten als 0.
y_pred_custom = (y_prob_class1 >= threshold).astype(int)
[125]:
# Evaluation der angepassten Vorhersagen:
from sklearn.metrics import accuracy_score, precision_score, recall_score
print("Accuracy:", accuracy_score(y_test, y_pred_custom))
print("Precision:", precision_score(y_test, y_pred_custom, pos_label=1))
print("Recall:", recall_score(y_test, y_pred_custom, pos_label=1))
Accuracy: 0.26587677725118486
Precision: 0.26587677725118486
Recall: 1.0